MQ 对比之 RabbitMQ vs Redis
目录
消息队列选择:RabbitMQ & Redis
RabbitMQ #
RabbitMQ是一个由erlang开发的AMQP(Advanced Message Queue )的开源实现的产品,RabbitMQ是一个消息代理,从“生产者”接收消息并传递消息至“消费者”,期间可根据规则路由、缓存、持久化消息。“生产者”也即message发送者以下简称P,相对应的“消费者”乃message接收者以下简称C,message通过queue由P到C,queue存在于RabbitMQ,可存储尽可能多的message,多个P可向同一queue发送message,多个C可从同一个queue接收message
RabbitMQ架构:
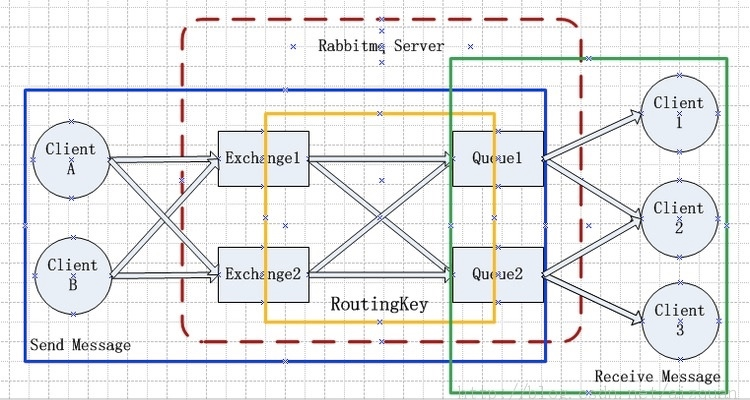
组件:
- Message (消息):RabbitMQ 转发的二进制对象,包括Headers(头)、Properties (属性)和 Data (数据),其中数据部分不是必要的;
- Producer(生产者): 消息的生产者,负责产生消息并把消息发到交换机Exhange的应用;
- Consumer (消费者):使用队列 Queue 从 Exchange 中获取消息的应用;
- Exchange (交换机):负责接收生产者的消息并把它转到到合适的队列;
- Queue (队列):一个存储Exchange 发来的消息的缓冲,并将消息主动发送给Consumer,或者 Consumer 主动来获取消息。
- Binding (绑定):队列 和 交换机 之间的关系。Exchange 根据消息的属性和 Binding 的属性来转发消息。绑定的一个重要属性是 binding_key。
- Connection (连接)和 Channel (通道):生产者和消费者需要和 RabbitMQ 建立 TCP 连接。一些应用需要多个connection,为了节省TCP 连接,可以使用 Channel,它可以被认为是一种轻型的共享 TCP 连接的连接。连接需要用户认证,并且支持 TLS (SSL)。连接需要显式关闭。
Redis #
Redis 是完全开源免费的,遵守BSD协议,是一个高性能的key-value数据库。
Redis 与其他 key - value 缓存产品有以下三个特点:
- Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
- Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
- Redis支持数据的备份,即master-slave模式的数据备份。
Redis 优势 #
- 性能极高 – Redis能读的速度是110000次/s,写的速度是81000次/s 。
- 丰富的数据类型 – Redis支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。
- 原子 – Redis的所有操作都是原子性的,意思就是要么成功执行要么失败完全不执行。单个操作是原子性的。多个操作也支持事务,即原子性,通过MULTI和EXEC指令包起来。
- 丰富的特性 – Redis还支持 publish/subscribe, 通知, key 过期等等特性。
首先Redis的设计是用来做缓存的,但是由于它自身的某种特性使得他可以用来做消息队列(Redis的List数据结构比较适合做MQ)。它有几个阻塞式的API可以使用,正是这些阻塞式的API让他有做消息队列的能力。 另外做消息队列的其他特性,例如FIFO也很容易实现,只需要一个list对象从头取数据,从尾部塞数据即可实现。 Redis能做消息队列得益于它的list对象blpop brpop接口以及Pub/Sub(发布/订阅)的某些接口。他们都是阻塞版的,所以可以用来做消息队列。
RabbitMQ和Redis的简单对比 #
RabbitMQ和Redis都可以做队列,但是他们还是有区别的。比如,Redis的消息队列,如果在从队列pop出去的时候,worker处理失败的话,数据不会回到队列中,需要从业务中手动把失败的处理数据push到队列中;而RabbitMQ可以自动处理失败的worker使数据不丢失;RabbitMQ还可以保证数据在传输过程中持久化,在通道和队列中的数据可以设置为持久化。首先Redis严格来说并不是消息队列,它是一个内存数据库,不过因为其某些特性适合用来充当队列,所以也多被用于做简单的mq, Redis之父倒是开发了个真正的消息队列disque,有兴趣可以看看。
相比起Redis,RabbitMQ有更加完善的MQ机制,这里我们仅讨论消息的durable(持久性),后续一系列其他机制有时间再交流。
RabbitMQ有一个消息确认机制来保证消息的不丢失:客户端从队列中取出消息之后,可能需要一段时间才能处理完成,如果在这个过程中,客户端出错了,异常退出了,而数据还没有处理完成,那么非常不幸,这段数据就丢失了,因为RabbitMQ默认会把此消息标记为已完成,然后从队列中移除,消息确认是客户端从RabbitMQ中取出消息,并处理完成之后,会发送一个ack告诉RabbitMQ,消息处理完成,当RabbitMQ收到客户端的获取消息请求之后,或标记为处理中,当再次收到ack之后,才会标记为已完成,然后从队列中删除。当RabbitMQ检测到客户端和自己断开链接之后,还没收到ack,则会重新将消息放回消息队列,交给下一个客户端处理,保证消息不丢失,也就是说,RabbitMQ给了客户端足够长的时间来做数据处理。
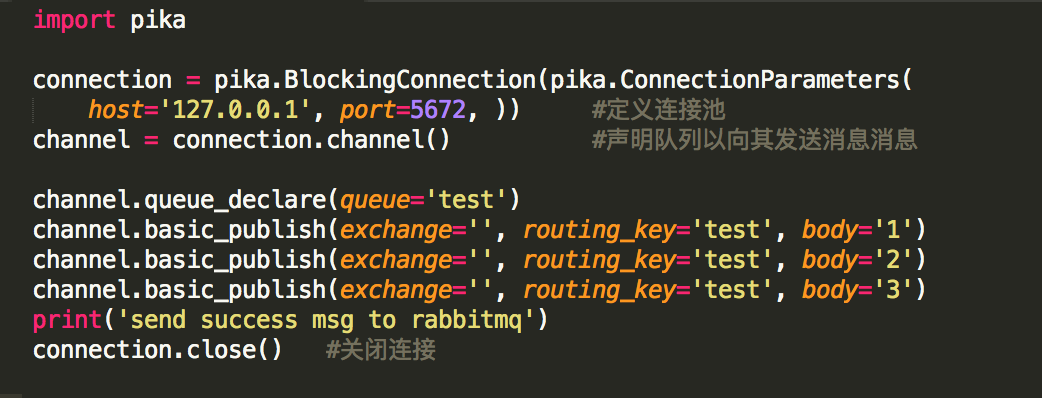
RabbitMQ demo之生产者消费者 #
生产者 #
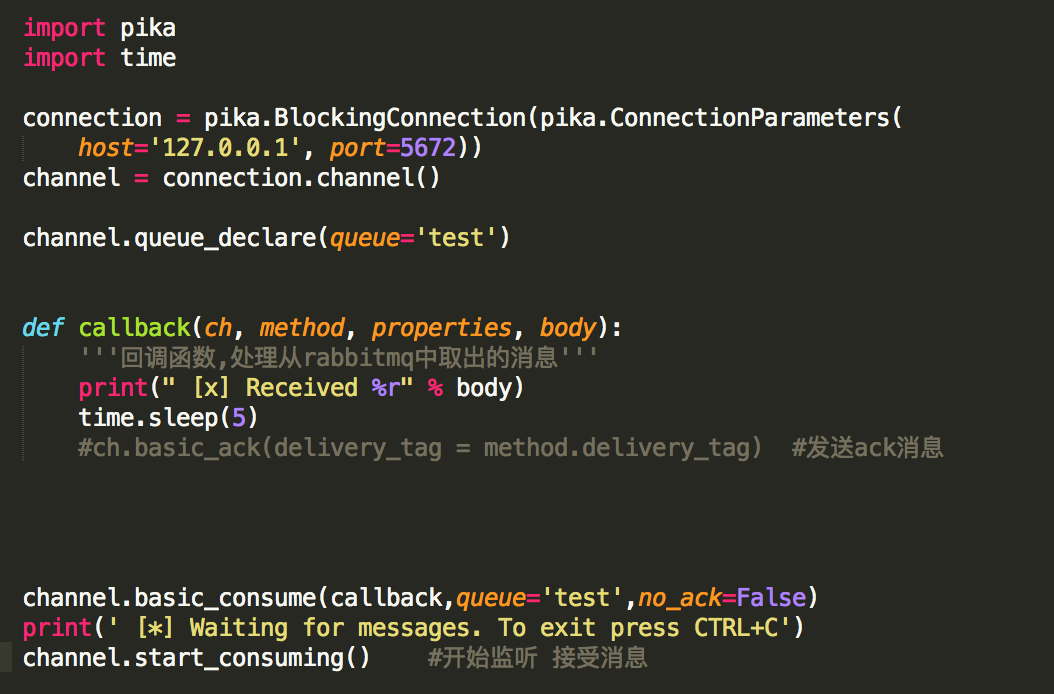
消费者(不发送ack,模拟程序中断) #
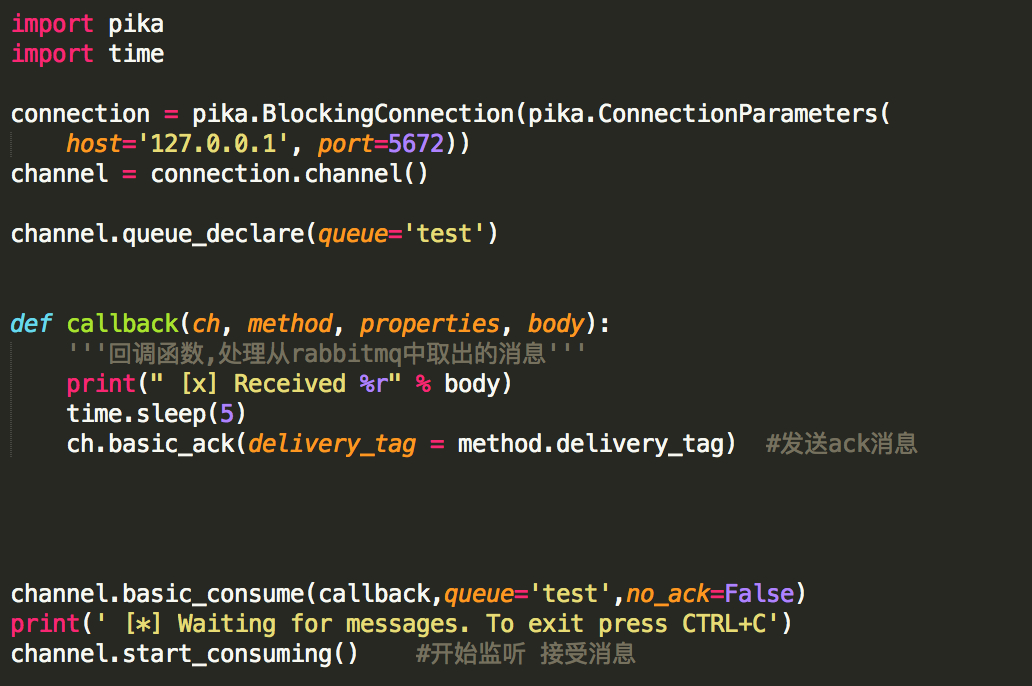
正常发送ack的消费者: #
关于RabbitMQ的其他features,如 Publish/Subscribe、Routing、Topics和RPC等,有兴趣可以Google。除了RabbitMQ除了Python的实践外,也可考虑其他语言的实践,这里提供另外一个语言golang的选择,可参考Ubuntu14.04+RabbitMQ3.6.3+Golang的最佳实践,这个文章讲的非常详尽,实践意义比较具有参考价值,有兴趣可以阅览一番。