Java 全文检索引擎工具包 Lucene 原理解析

目录
Lucene 是什么? #
Lucene 是 apache 软件基金会 4 jakarta 项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。Lucene 的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。Lucene是一套用于全文检索和搜寻的开源程式库,由Apache软件基金会支持和提供。Lucene 提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。在 Java 开发环境里 Lucene 是一个成熟的免费开源工具。就其本身而言,Lucene 是当前以及最近几年最受欢迎的免费 Java 信息检索程序库。人们经常提到信息检索程序库,虽然与搜索引擎有关,但不应该将信息检索程序库与搜索引擎相混淆。
简单来说,Lucene 提供了一套完整的工具来帮助开发者构建自己的搜索引擎,开发者只需要 import Lucene 对应的 package 即可快速地开发构建自己的业务搜索引擎。
Lucene 中的基本概念: #
- 索引(Index):文档的集合组成索引。和一般的数据库不一样,Lucene 不支持定义主键,但 Solr 支持。
- 为了方便索引大量的文档,Lucene 中的一个索引分成若干个子索引,叫做段(segment)。段中包含了一些可搜索的文档。
- 文档(Document):代表索引库中的一条记录。一个文档可以包含多个列(Field)。和一般的数据库不一样,一个文档的一个列可以有多个值。例如一篇文档既可以属于互联网类,又可以属于科技类。
- 列(Field):命名的词的集合。
- 词(Term) :由两个值定义——词语和这个词语所出现的列。
- 倒排索引是基于词(Term)的搜索。
关于倒排索引 #
要学习搜索引擎,就需要了解倒排索引,要更加深刻地理解倒排索引,就要先了解什么是正排索引(表)。
正排索引(正向索引) #
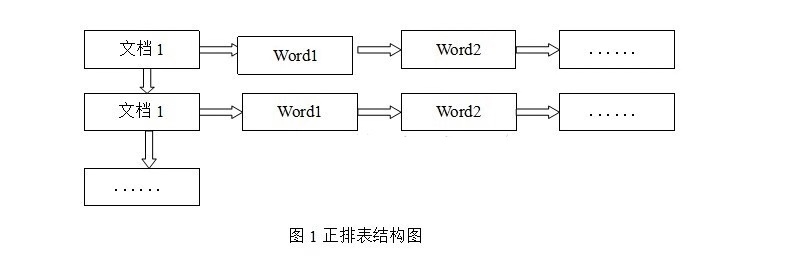
正排表是以文档的 ID 为关键字,表中记录文档中每个字的位置信息,查找时扫描表中每个文档中字的信息直到找出所有包含查询关键字的文档。
正排表结构如图 1 所示,这种组织方法在建立索引的时候结构比较简单,建立比较方便且易于维护;因为索引是基于文档建立的,若是有新的文档加入,直接为该文档建立一个新的索引块,挂接在原来索引文件的后面。若是有文档删除,则直接找到该文档号文档对应的索引信息,将其直接删除。但是在查询的时候需对所有的文档进行扫描以确保没有遗漏,这样就使得检索时间大大延长,检索效率低下。
尽管正排表的工作原理非常的简单,但是由于其检索效率太低,除非在特定情况下,否则实用性价值不大。
倒排索引(反向索引) #
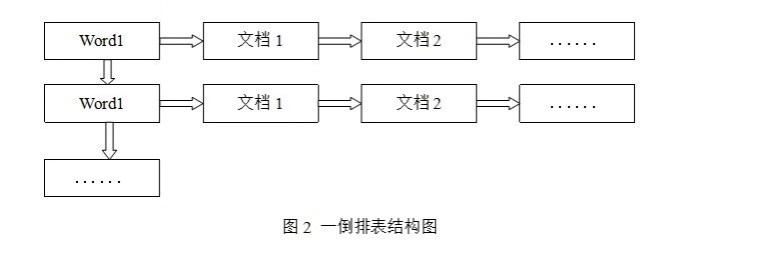
倒排表以字或词为关键字进行索引,表中关键字所对应的记录表项记录了出现这个字或词的所有文档,一个表项就是一个字表段,它记录该文档的 ID 和字符在该文档中出现的位置情况。
由于每个字或词对应的文档数量在动态变化,所以倒排表的建立和维护都较为复杂,但是在查询的时候由于可以一次得到查询关键字所对应的所有文档,所以效率高于正排表。在全文检索中,检索的快速响应是一个最为关键的性能,而索引建立由于在后台进行,尽管效率相对低一些,但不会影响整个搜索引擎的效率。
搜索引擎通常检索的场景是:给定几个关键词,找出包含关键词的文档。 怎么快速找到包含某个关键词的文档就成为搜索的关键。这里我们借助单词——文档矩阵模型, 通过这个模型我们可以很方便知道某篇文档包含哪些关键词,某个关键词被哪些文档所包含。 单词-文档矩阵的具体数据结构可以是倒排索引、签名文件、后缀树等。
倒排索引源于实际应用中需要根据属性的值来查找记录,lucene 是基于倒排索引实现的。 这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。 由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引(inverted index)。 带有倒排索引的文件我们称为倒排索引文件,简称倒排文件(inverted file)。 倒排索引一般表示为一个关键词,然后是它的频度(出现的次数),位置(出现在哪一篇文章或网页中,及有关的日期,作者等信息),它相当于为互联网上几千亿页网页做了一个索引,好比一本书的目录、标签一般。读者想看哪一个主题相关的章节,直接根据目录即可找到相关的页面。不必再从书的第一页到最后一页,一页一页的查找。
依据上面的原理,假设有这么两篇文档:
- 文档 1: When in Rome, do as the Romans do.
- 文档 2: When do you come back from Rome?
停用词: in, as, the, from。(在信息检索中,为节省存储空间和提高搜索效率,在处理自然语言数据(或文本)之前或之后会自动过滤掉某些字或词,这些字或词即被称为 Stop Words(停用词)。)
把这两篇文档拆解转化为倒排索引如下:
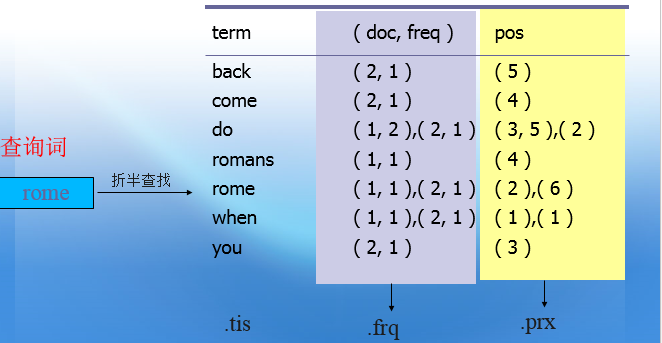
现在检索的时候就可以利用倒排索引的优势大大提高效率:假如查询 back 这个单词,通过上面的倒排索引,可以直接定位到它出现在文档 2 中,且出现了 1 次(频率),出现的位置是文档的第 5 个单词,一目了然,相较于正排索引,也即是以文档为基本查询单位的结构,倒排索引能够更快地定位到 keyword 的所在,极大提高检索响应速度。
Lucene 的索引检索流程 #
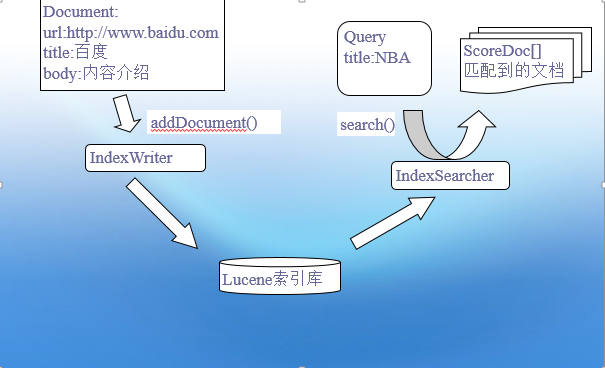
首先把信息建立索引库(原始信息一般由网络爬虫获得),通过 Lucene 的 IndexWriter 写入倒排索引建立索引库,当有 query 请求时,通过 IndexSearcher 解析、匹配,从索引库获得结果返回并排序。
1.索引 #
索引相关类 #

- 一个 Document 代表索引库中的一条记录。一个 Document 可以包含多个列。例如一篇文章可以包含“标题”、“正文”、“修改时间”等 field,创建这些列对象以后,可以通过 Document 的 add 方法增加这些列到 Document 实例。
- 一段有意义的文字通过 Analyzer 分割成一个个的词语后写入到索引库。
创建索引 #
//创建新的索引库
IndexWriter index = new IndexWriter(indexDirectory,//索引库存放的路径
new StandardAnalyzer(Version.LUCENE_CURRENT),
true,//新建索引库
IndexWriter.MaxFieldLength.UNLIMITED);//不限制列的长度
File dir = new File(sourceDir);
indexDir(dir); //索引sourceDir路径下的文件
index.optimize();//索引优化
index.close();//关闭索引库
向索引增加文档 #
一个索引和一个数据库表类似,但是数据库中是先定义表结构后使用。但 Lucene 在放数据的时候定义字段结构。
Document doc = new Document();
//创建网址列
Field f = new Field(“url”, news.URL , //news.URL 存放url地址的值
Field.Store.YES, Field.Index. NOT_ANALYZED,//不分词
Field.TermVector.NO);
doc.add(f);
//创建标题列
f = new Field(“title”, news.title , //news.title 存放标题的值
Field.Store.YES, Field.Index.ANALYZED,//分词
Field.TermVector.WITH_POSITIONS_OFFSETS);//存Token位置信息
doc.add(f);
//创建内容列
f = new Field(“body”, news.body , //news.body 存放内容列的值
Field.Store.YES, Field.Index. ANALYZED, //分词
Field.TermVector.WITH_POSITIONS_OFFSETS); //存Token位置信息
doc.add(f);
index.addDocument(doc); //把一个文档加入索引
2.检索 #
查询语法 #
- 加权: “dog^4 cat”,^ 表示加权
- 修饰符: + - NOT, 例如, “+dog cat”
- 布尔操作符: OR AND, 例如, “(dog OR cat) AND mankind”
- 按域查询: title:apple, 一个字段名后跟冒号,再加上要搜索的词语或者短句,就可以把搜索条件限制在该字段。
QueryParser #
- QueryParser 将输入查询字串解析为 Lucene Query 对象。
- QueryParser 是使用 JavaCC(Java Compiler Compiler )工具生成的词法解析器。
- QueryParser.jj 中定义了查询语法。
分析器(Analyzer) #
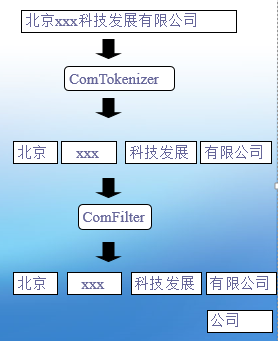
全文索引是按词组织的,所以在一长串 keyword 输入之后需要对其进行切分,Lucene 中把索引中的词称为 token,Analyzer 会通过内部的 Tokenizer 把 keyword 解析成词序列,也就是 token 流,以供检索使用,可以使用 Filter 来过滤最后的查询结果。Lucene 在两个地方使用到 Analyzer:索引文档的时候和按 keyword 检索文档的时候。索引文档的时候 Analyzer 解析出的 token(词)即为倒排表中的词。
分析公司名的流程
Analyzer analyzer = new CompanyAnalyzer();
TokenStream ts = analyzer.tokenStream("title", new StringReader("北京xxx科技发展有限公司"));
while (ts.incrementToken()) {
System.out.println("token: "+ts));
}
搜索 #
IndexSearcher isearcher = new IndexSearcher(directory,//索引路径
true); //只读
//搜索标题列
QueryParser parser = new QueryParser(Version.LUCENE_CURRENT,"title", analyzer);
Query query = parser.parse(“NBA”); //搜索NBA这个词
//返回前1000条搜索结果
ScoreDoc[] hits = isearcher.search(query, 1000).scoreDocs;
//遍历结果
for (int i = 0; i < hits.length; i++) {
Document hitDoc = isearcher.doc(hits[i].doc);
System.out.println(hitDoc.get("title"));
}
isearcher.close();
directory.close();
常用的查询类型:
1. 最基本的词条查询-TermQuery: 一般用于查询不切分的字段或者基本词,即全匹配。
IndexSearcher isearcher = new IndexSearcher(directory, true);
//查询url地址列
Termterm = new Term("url","http://www.lietu.com");
TermQuery query = new TermQuery(term);
//返回前1000条结果
ScoreDoc[] hits = isearcher.search(query, 1000).scoreDocs;
2. 布尔逻辑查询-BooleanQuery: 同时查询标题列和内容列。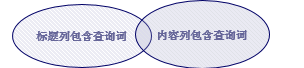
QueryParser parser = new QueryParser(Version.LUCENE_CURRENT, "body", analyzer);
QuerybodyQuery = parser.parse("NBA");//查询内容列
parser = new QueryParser(Version.LUCENE_CURRENT, "title", analyzer);
QuerytitleQuery = parser.parse("NBA");//查询标题列
BooleanQuery bodyOrTitleQuery = new BooleanQuery();
//用OR条件合并两个查询
bodyOrTitleQuery.add(bodyQuery, BooleanClause.Occur.SHOULD);
bodyOrTitleQuery.add(titleQuery, BooleanClause.Occur.SHOULD);
//返回前1000条结果
ScoreDoc[] hits = isearcher.search(bodyOrTitleQuery, 1000).scoreDocs;
布尔查询的实现过程如下: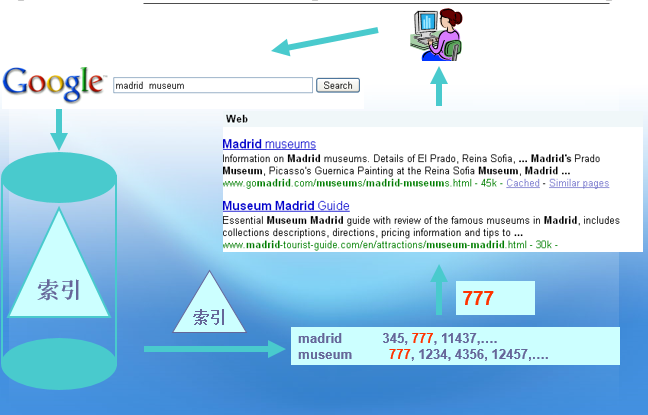
3. RangeQuery-区间查找: 例如日期列 time 按区间查询的语法, time:[2007-08-13T00:00:00Z TO 2008-08-13T00:00:00Z]
后台实现代码:
ConstantScoreRangeQuery dateQuery = new ConstantScoreRangeQuery("time", t1, t2, true,
true);
旧版本区间查询的问题 #
RangeQuery 采用扩展成 TermQuery 来实现,如果查询区间范围太大,RangeQuery 会导致 TooManyClausesException ConstantScoreRangeQuery 内部采用 Filter 来实现,当索引很大的时候,查询速度会很慢
Trie 结构实现的区间查询 #
在 Lucene2.9 以后的版本中,用 Trie 结构索引日期和数字等类型。例如:把 521 这个整数索引成为:百位是 5、十位是 52、个位是 521。这样重复索引的好处是可以用最低的精度搜索匹配区域的中心地带,用较高的精度匹配边界。这样减少了要搜索的 Term 数量。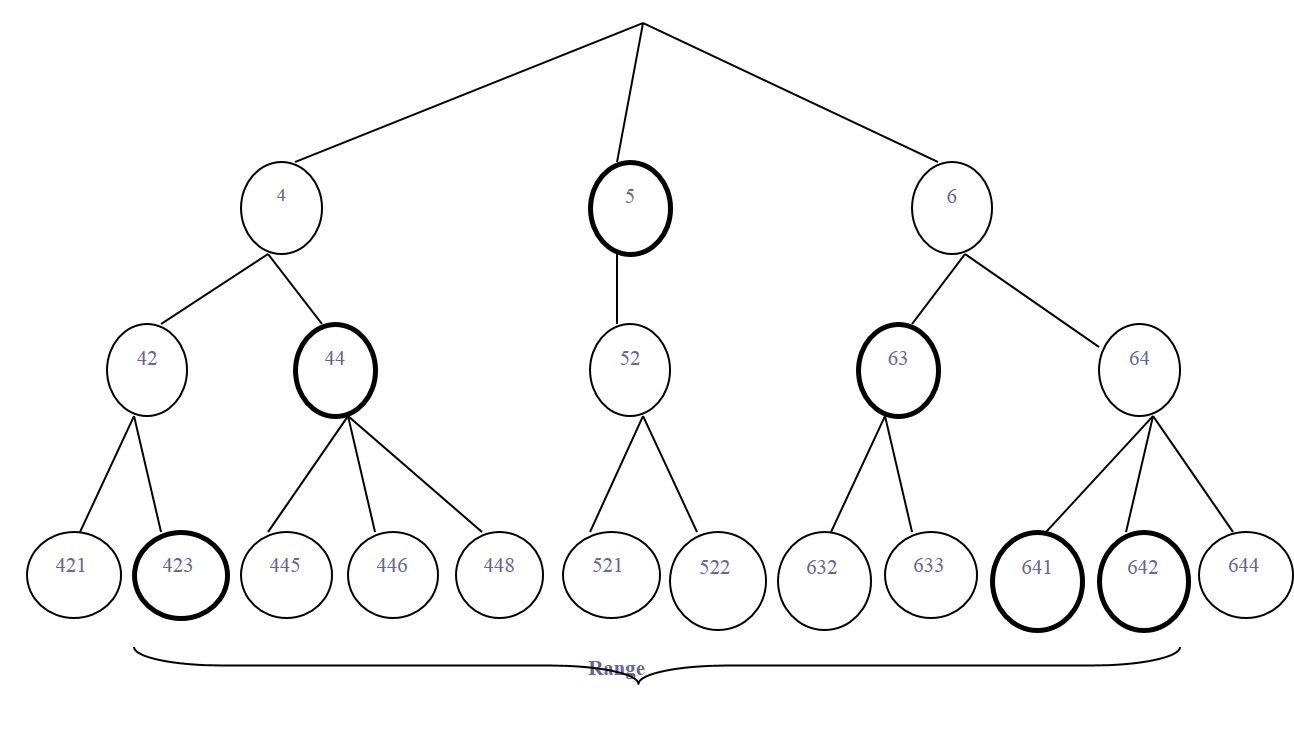
Trie 结构区间查询 #
例如:TrieRange:[423 TO 642] 分解为 5 个子条件来执行: handreds:5 OR tens:[43 TO 49] OR ones:[423 TO 429] OR tens:[60 TO 63] OR ones:[640 TO 642]
使用 Trie 结构实现的区间查询 #
- 索引时,增加一个浮点数列到索引:
document.add(new NumericField("weight").setFloatValue(value)); - 搜索时,使用 NumericRangeQuery 来查询这样的数字列。例如:
Query q = NumericRangeQuery.newFloatRange(“weight”, new Float(0.3f), new Float(0.10f), true, true);weight:列名称,new Float(0.3f):最小值从它开始,new Float(0.10f):最大值到它结束,true:是否包含最小/大值。
用压缩来改进搜索性能 #
压缩的原理 #
因为存在冗余,所以可以压缩。压缩的原理:使用预测编码,对前后相似的内容压缩。 压缩的对象
- 字符串数组(Term List)
- 整数数组(DocId)
字符串数组排序后使用前缀压缩,整数数组排序后使用差分编码压缩 。压缩算法的两个过程:编码(压缩)过程和解码(解压缩)过程。编码过程可以时间稍长,解码过程需要速度快。类似 ADSL 上网机制:下载速度快,而上传速度慢。因为在索引数据阶段执行编码过程,而在搜索阶段执行解码过程。索引数据速度可以稍慢,但是搜索速度不能慢。
**前缀编码(Front Encoding)** #
因为索引词是排序后写入索引的,所以前后两个索引词词形差别往往不大。前缀压缩算法省略存储相邻两个单词的共同前缀。每个词的存储格式是: < 相同前缀的字符长度,不同的字符长度,不同的字符 >。
例如:顺序存储如下三个词:term、termagancy、termagant。不用压缩算法的存储方式是 < 词长,词 >,例如: <4,term> <10,termagancy> <9,termagant>;应用前缀压缩算法后,实际存储的内容如下: <4,term> <4,6, agancy> <8,1,t>。
差分编码(Differential Encoding) #
变长压缩算法对于较小的数字有较好的压缩比。差分编码可以把数组中较大的数值用较小的数来表示,所以可以和变长压缩算法联合使用来实现数组的压缩。
编码过程 #
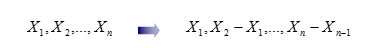
解码过程 #
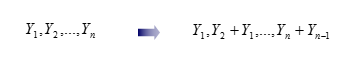
变长压缩(Variable byte encoding) #


VInt 是一个变长的正整数表示格式,是一种整数的压缩格式表示方法。每字节分成两部分:最高位和低 7 位。最高位表明是否有更多的字节在后面,0 表示这个字节是尾字节,1 表示还有后续字节,低 7 位表示数值。按如下的规则编码正整数 x:
- if (x < 128),则使用一个字节(最高位置 0,低 7 位表示数值);
- if (x< 128*128),则使用 2 个字节(第一个字节最高位置 1,低 7 位表示低位数值,第二个字节最高位置 0 ,低 7 位表示高位数值);
- if (x<128^3),则使用 3 个字节,以此类推,把 VInt 看成是 128 进制的表示方法,低位优先,随着数值的增大,向后面的字节进位。
Lucene 源码结构 #

参考 #
[1] Michael McCandless, Erik Hatcher, Otis Gospodnetic 著;Lucene in Action(Second Edition);电子工业出版社,2011
[2] (美)W Bruce Croft 著,刘挺 秦兵 译;搜索引擎:信息检索实践 畅销书籍 科技 正版搜索引擎 信息检索实践;机械工业出版社,2010
[3] (日)山田浩之 (日)末永匡 著,胡屹 译;自制搜索引擎;人民邮电出版社,2016