Socket 编程之 SO_REUSEADDR & SO_REUSEPORT 精粹
目录
导言 #
SO_REUSEADDR 和 SO_REUSEPORT 是 socket 编程中非常重要的两个套接字选项,同时也在实际的网络编程中经常会用到。从名字能够大概了解这两个选项的功能:前者是重用地址,后者是重用端口;概括一下就是,前者允许以相同的端口绑定不同的地址,后者允许以相同的地址再绑定相同的端口。
这两个套接字选项都是基于现实的网络编程问题而设计出来的,我会在本文中分析这两个选项实际解决的问题,能为网络编程带来哪些优势,其本身又有哪些劣势和副作用。最后我会再讲一讲这两个套接字选项在类 Unix 操作系统的不同平台上的实现有哪些异同,希望能为读者以后编写跨平台的可移植程序提供一点启发和参考。
IP 五元组 #
介绍 SO_REUSEADDR 和 SO_REUSEPORT 之前有必要先来复习一下 [TCP|UDP]/IP 里的一个基本概念:一个 TCP 连接或者一次 UDP 传输用一个五元组来唯一确定:<source IP address, source IP port, destination IP address, destination IP port, transport protocol>1,也就是源地址、源端口、目的地址、目的端口,以及传输协议。
通常我们进行 socket 编程时建立连接所使用几个基本系统调用是:socket()2、bind()3、connect()4、listen()5 和 accept()6。其中,socket() 用来选择传输协议,bind() 用来选择源地址和端口,connect() 用来选择目的地址和端口 (如果之前没有调用 bind() 则由 connect() 来自动选择一个可用的 IP 和一个临时的端口),listen() 用来把 socket() 创建的主动 (active) 套接字转化成一个被动 (passive) 套接字,如果之前没有调用 bind() 绑定一个端口,那么 listen() 就会选择一个临时端口,accept() 接受对端的 connect() 并创建新的服务端 socket。当然,这里主要是以 TCP 为例,如果是 UDP 这种无连接的 socket (UDP 实际上也可以建立 “连接”,但这是另一个话题了,有空再聊),则通常可以不需要调用 connect() 和 listen() 而直接进行数据收发。发送数据的时候系统会自动为客户端选择有效的地址和临时端口。
IPv4/IPv6 中有两个重要的概念:INADDR_ANY 和 INPORT_ANY,前者表示任意地址,后者表示任意端口。前者的值是 0.0.0.0 —— IPv4,:: —— IPv6;后者的值是 0。因为一个 socket 确实可以绑定系统中的所有网卡地址,所以 INADDR_ANY 也被称之为通配地址7 (wildcard address),这个地址可以用来为一个 socket 绑定当前系统的所有地址,而 socket 不能真的绑定系统中的所有端口, 所以使用 INPORT_ANY 为一个 socket 绑定端口的时候,系统会在当前可用的端口中随机挑选一个。
默认情况下,五元组的唯一性决定了源地址和端口只能被绑定一次,也就是不能有两个 sockets 同时绑定到相同的本地 IP 地址和端口。而如果一个 socket 绑定了 INADDR_ANY 和某一个端口,那就是绑定了当前系统中所有的 IP 地址,其他 socket 除非换端口,否则无法进行绑定。比如一个 socket 绑定了 0.0.0.0:80,那么你再创建一个 socket 绑定 127.0.0.1 会失败,因为 INADDR_ANY 的语义就覆盖了所有的本地 IP 地址。
SO_REUSEADDR #
SO_REUSEADDR 通过系统调用 setsockopt()8 为 socket 设置。这个套接字选项究其根本,处理的就是 INADDR_ANY 以及 TCP 的 ESTABLISHED、TIME-WAIT 状态下的地址重用问题。
以最早的 BSD socket 实现为例,这个套接字选项的使用场景归纳起来主要有以下四种:
- 主机上多个进程重用地址绑定相同的端口:假设本地主机的 IP 地址为
198.69.10.2,但是这个地址有两个别名198.69.10.128和198.69.10.129。现在启动三个 HTTP 服务器,第一个调用bind()绑定INADDR_ANY和 80 端口;第二个也调用bind()绑定198.69.10.128和 80 端口,这时候第二个服务器会启动失败,bind()返回EADDRINUSE错误,但是如果第二个服务器在调用bind()之前先设置SO_REUSEADDR,那么bind()就不会失败;第三个服务器也提前设置SO_REUSEADDR之后再调用bind(),同样可以成功启动。至此,三个服务器都启动了,此时客户端请求过来了,HTTP 请求所在的 TCP 连接的目的地址和端口如果是198.69.10.128:80,则会被投送到第二个服务器,如果是198.69.10.129:80则被投送到第三个服务器,如果是198.69.10.2:80或者其他目的端口为 80 的所有 IP 地址则都会被投送到第一个服务器。因为INADDR_ANY本身就包含了本机的所有的可用地址,默认情况下所有发送到本机的数据都会送到绑定了该通配地址的 socket 中去,除非有其他特殊的指定,就比如我们这个场景。 - 主机上单个进程重用地址绑定相同端口:和上一个场景类似,只不过是单个进程内使用。之所以要这么做,主要是因为有某些操作系统不支持服务端获取 UDP socket 的远端地址,所以通过将不同的地址绑定到不同的 socket,可以手动区分数据是来自哪个对端。
- 主机上的服务器程序快速重启之后重用地址绑定相同的端口:前面的两个例子属于
SO_REUSEADDR处理INADDR_ANY那一类的问题。而这个例子则是关于 TCP 的 ESTABLISHED、TIME-WAIT 状态下的地址重用问题,重启的问题又可以分成两类:- 启动一个服务器监听
198.69.10.2:80,有一个客户端请求建立连接,accept()之后创建子进程去处理这个 TCP 连接,然后关闭 listener socket 之后退出父进程并进行重启,同时保留子进程,重启过程中bind()会失败,因为此时子进程中绑定198.69.10.2:80这个连接还在,而且还是ESTABLISHED状态,要注意accept()之后的 socket 对应的连接的本地地址和端口和 listener socket 是一样的,此时系统不允许新的进程绑定这个地址和端口,但是如果设置了SO_REUSEADDR的话就可以bind()成功。通常建议所有的 TCP 服务器都设置SO_REUSEADDR以应对这种情况。 - 启动一个服务器监听
198.69.10.2:80,正常处理客户端连接,然后关闭 listener socket 并快速重启进程。在 listener socket 彻底关闭之前会长时间 (2MSL) 停留在 TIME-WAIT 状态9,此时重启的进程试图绑定198.69.10.2:80的时候就会失败,因为 系统不允许TIME-WAIT 状态的连接被重用,因为可能会导致新连接上会有残留旧连接的报文从而对新连接造成污染10。因此当旧的 listener socket 处于 TIME-WAIT 状态时,就无法用新的 listener socket 再对相同的地址和端口再进行bind(),除非提前为新 listener socket 设置SO_REUSEADDR。要注意使用SO_REUSEADDR绕过 TIME-WAIT 限制强行重新绑定相同的地址和端口有潜在的未知风险,除了前文提及的数据污染的问题10,还可能会有更严重的问题,比如要是旧连接上有非法报文,还会导致 TCP 发送 RST 报文终止连接11。因此,这个使用方法要非常谨慎地使用。
- 启动一个服务器监听
- 正如前面所说,
SO_REUSEADDR这个套接字选项主要是为了处理通配地址和具体地址的冲突,比如它允许两个 socket 可以分别绑定0.0.0.0:80和127.0.0.1:80,但是不能用于 TCP 完全重复的地址绑定 (completely duplicate binding),比如两个 socket 都要192.69.10.128:80的话,通常来说SO_REUSEADDR也帮不上忙。但是,在某一些传输协议的特殊场景中却可以支持这种做法,比如 UDP 的多播功能:将SO_REUSEADDR用于 UDP 多播时,系统允许在同一个主机上同时运行多个绑定相同地址和端口的进程,如果此时有一个 UDP 数据报到来,系统根据这个规则选择将报文投送到哪里:如果该报文的目的地址是一个广播地址或者多播地址的话,那么就给每一个匹配的 socket 都投送一份该数据报的副本;但是如果该报文的目的地址是一个单播地址,那么就只将数据报投送到一个 socket 上,如果有多个 socket 符合条件,那么投送到哪一个取决于具体的 UDP 协议实现。
值得一提的一点是,SO_REUSEADDR 只需要在那些要进行地址重用的 socket 上设置即可,比如上面的第一个场景中的三个 HTTP 服务器,第一个服务器不需要设置这个套接字选项,只需要后面的第二第三个服务器启动的时候设置就行了。
最后,SO_REUSEADDR 存在一种称之为端口劫持 (port hijacking) 的安全问题:假设一开始一个进程 A 已经用了通配地址 (0.0.0.0) 绑定了端口 8080,本来是期望接收并处理所有发到本机 8080 端口的数据包的,但是后面有另一个进程 B 设置了 SO_REUSEADDR 并用其他的地址比如 192.69.10.128 绑定 8080 端口,那么后续目的地址为 192.69.10.128 和 8080 端口的数据包就会被投送到进程 B 中去,相当于进程 B 劫持了进程 A 的端口。对于大多数常用的网络服务比如 HTTP、FTP、SSH 和 Telnet 等来说,这不成问题,因为这些服务使用的通常都是系统的保留端口,也就是小于 1024 的端口12:
The TCP/IP port numbers below 1024 are special in that normal users are not allowed to run servers on them. This is a security feaure, in that if you connect to a service on one of these ports you can be fairly sure that you have the real thing, and not a fake which some hacker has put up for you.
这些端口只有 root 用户或者具有 root 权限的用户才可以使用,所以不会随便被普通用户实施端口劫持。而那些使用了大于等于 1024 端口号作为默认端口的服务就会有端口劫持的风险,比如 MySQL 的 3306 默认端口。
SO_REUSEPORT #
SO_REUSEPORT 这个套接字选项最早由 4.4BSD 引入,主要是为了弥补 SO_REUSEADDR 缺失的完全重复的地址绑定 (completely duplicate binding) 支持。但要注意的是,SO_REUSEPORT 的语义并没有覆盖 SO_REUSEADDR,也就是说,前者应该仅应用于完全重复的地址绑定,而如果是通配地址和具体地址的重复绑定还是应该用后者,而且这两个选项之间还有以下的异同:
- 如果要设置
SO_REUSEPORT,那么必须给每一个 socket 都设置,否则不起作用;而SO_REUSEADDR则只需要设置那个重复绑定地址的 socket 即可。 - 如果要绑定的是一个多播地址,则
SO_REUSEADDR和SO_REUSEPORT是完全等效的。
另一个值得说的点是,SO_REUSEPORT 还可能会导致客户端的 connect() 调用失败并返回 EADDRINUSE。这里读者可能会有疑问,因为 这个错误通常是 bind() 返回的,而我们前面介绍的 SO_REUSEADDR 和 SO_REUSEPORT 就是用来解决这个错误的,怎么 connect() 也会出现这个错误?正如前文所述,一条连接是由一个五元组唯一确定的,所以如果你使用了 SO_REUSEPORT 在多个 sockets 上都绑定了完全一样的源地址和端口,那么这多个五元组中的三个元素就会是完全一样的,这个时候再调用 connect() 补上目的地址和端口之时,就会存在多个完全相同的五元组,这种情况是不允许的,否则的话,当系统接收到网络数据的时候,它根本不知道应该把数据投送给哪个 socket,因为这些 socket 的五元组中的地址都是一样的,所以在调用 connect() 时就会提前返回 EADDRINUSE 错误,禁止这种行为。
平台异同 #
Linux #
Linux 上的 SO_REUSEADDR 实现有点别扭,它的使用需要分两种情况讨论:
如果是客户端 socket 使用,那么
SO_REUSEADDR和我们前文所述的 BSD socket 实现是一致的,而且如果每一个 socket 都设置了这个选项,那么它的作用是和 BSD 的SO_REUSEPORT一样的。之所以如此设计,是因为 Linux 3.9 之前并不支持SO_REUSEPORT,所以 Linux 暂时先扩展了SO_REUSEADDR的语义。如果是服务端 socket 使用,则
SO_REUSEADDR就是无效的。也就是说如果有一个 passive socket 正在监听一个端口,那么即便设置SO_REUSEADDR也无法再绑定这个端口,无论是用哪一个本地地址。比方说,如果有一个 socket 绑定了0.0.0.0:9090并调用了listen()进行监听,那么第二个 socket 就算设置了SO_REUSEADDR也无法绑定127.0.0.1:9090。上面说的客户端层面的使用也受到这一条规则的限制,也就是说客户端 socket 使用SO_REUSEADDR和 BSD socket 的实现保持一致的前提是当前没有一个 listening socket 正在监听客户端 socket 要绑定的端口。然而,Linux 的 man page 上写的是 “except when there is an active listening socket bound to the address”13,也就是说,SO_REUSEADDR还是可以用来解决快速重启强制绑定处于 TIME-WAIT 状态的连接问题。
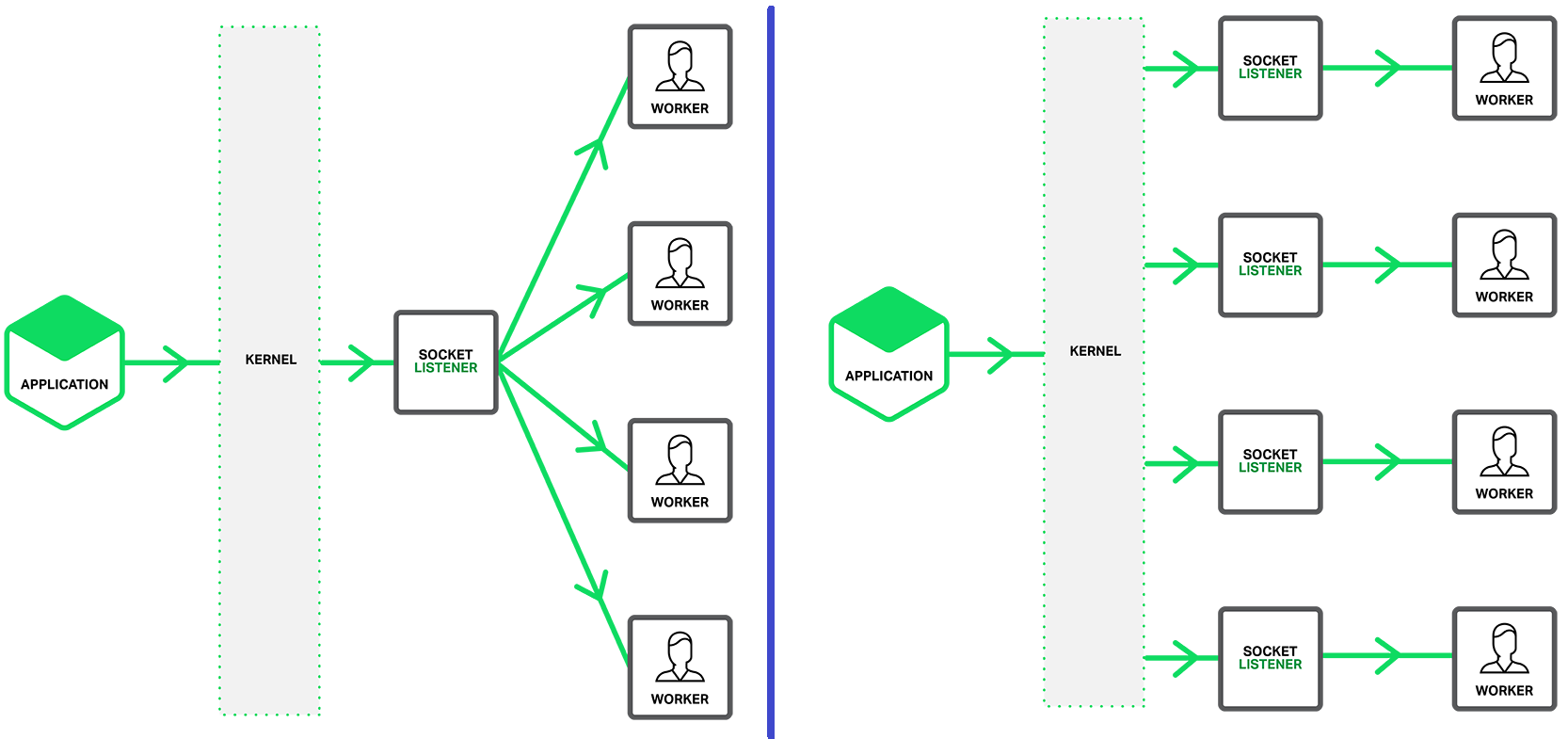
Linux 在 3.19 版本中支持了 SO_REUSEPORT14,但是其实现却破坏了这个套接字选项的原始语义,除了提供 completely duplicate binding 的支持,它还为 TCP 和 UDP socket 提供了一套内核负载均衡的功能:多个 sockets 可以监听同一个 IP 和端口,之后内核就会将新来的 (TCP) 连接或者 (UDP) 数据报平均地分发给这些 sockets。之所以要增加这个支持,主要是为了解决多线程 (进程) 下 accept() (TCP) 和 recv() (UDP) 系统调用的横向扩展性的问题:单线程 (进程) 监听一个地址并处理所有新来的 (TCP) 连接或者 (UDP) 数据报会有性能瓶颈,所以很多程序会使用多线程 (进程) 来同时调用 accept() 或者 recv(),但是这种使用模式存在惊群问题 (thundering herd problem),导致所有线程会被唤醒去竞争一个事件15,以 TCP 为例,也就是说所有阻塞在 accept() 系统调用上的线程都会被唤醒,然后一起竞争一个新连接,最终只会有一个线程能拿到这个连接,而且这个过程中内核是会为 accept queue 加锁的,这样不仅是多出来了很多没必要的系统调用开销,而且因为锁竞争又浪费 CPU 资源。因此,Linux 为 SO_REUSEPORT 提供了这种负载均衡的功能,这样多线程 (进程) 就可以各自使用自己的 socket 监听同一个地址并拥有自己的 accept queue,不会造成锁竞争,而且新连接会被平均地分发到各个 socket 上,从而解决横向扩展性的问题。这个能力对于大型的网络系统来说非常有用,可以极大地提升网络吞吐性能,比如 nginx 在 1.9.1 版本中就用上了这个负载均衡的能力,这是前后的架构对比16:
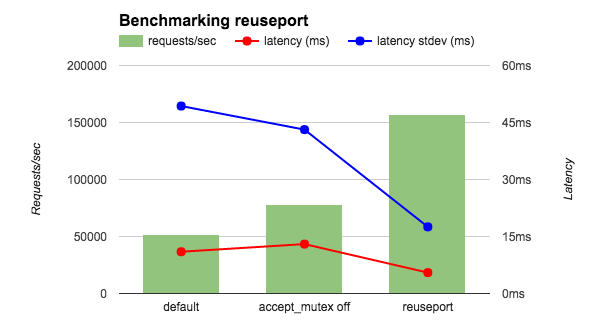
开启了 SO_REUSEPORT 之后 nginx 的网络性能得到了极大地提升16:
为什么说 Linux 的实现破坏了 SO_REUSEPORT 的原始语义呢?正如我在上一篇文章《TCP Keep-Alives 的原理和应用》中所讲的,目前所有操作系统上的 socket 实现都是衍生自 BSD socket17,我们可以再回过头来看看 SO_REUSEADDR 的语义,从前文的描述不难看出来,使用了这个套接字选项的后一个 socket 实际上是从前一个 socket “接管"了那些发送到目的地址的流量,而 BSD 定义和实现的 SO_REUSEPORT 继承了 SO_REUSEADDR 这部分语义:多个 sockets 绑定了同一个地址和端口,未来所有的这个目的地址和端口的网络包都会由最后一个绑定这个地址和端口的 socket 接收,而 Linux 实现的 SO_REUSEPORT 则是"共享"了这些流量:分发给了所有绑定了同一个地址和端口的 sockets。
然而,Linux SO_REUSEPORT 的这个负载均衡功能有两个问题:
- 由于内核的负载均衡策略是基于 <source IP address, source IP port, destination IP address, destination IP port> 这个四元组计算出一个哈希值,然后用这个哈希值来决定把新来的网络连接 (TCP) 或者网络报文 (UDP) 投送给哪一个 socket,所以如果客户端使用了相同的源地址和端口的话,那么这个客户端所发送的所有数据就都会被投送到同一个服务端 socket 中去,此时负载均衡失效。
- 对于 TCP 来说,如果有多个进程的 listening sockets 使用了
SO_REUSEPORT监听同一个地址和端口,然后在程序运行期间有一些进程退出了或者有新的进程加入了,这可能会导致内核丢弃那些还没有完成三次握手并进入在 accept queue 中的连接14,这个主要是因为内核决定新连接交由哪个 listening socket 去处理的时候是基于哈希值和 socket 数组:根据四元组算出一个哈希值然后根据 socket 数组长度进行取模得到一个 index,接着根据这个 index 从数组中取出对应的 listening socket。如果后端的 listening sockets 数量发生变化,则 socket 数组就会变化,从而先前计算得到的 index 可能就会对不上,导致在连接的三次握手期间可能会出现这样的情况:客户端的 SYN 抵达服务端的时候算出来一个 index,然后被发到某一个 listening socket,连接先进入其 SYN queue,然后这时候其中一个 listening socket 所在的进程退出了导致内核中的 sockets 数组更新,于是三次握手最后的 ACK 因为 socket 数组的更新从而使得其根据 index 路由过去的是另一个 listening socket,然后这个连接就会被 RST 信号重置。
最后,还记得我前面介绍过的端口劫持的问题吗?Linux 的 SO_REUSEPORT 为了防止这个问题,还加了一个限制:所有使用这个套接字选项绑定相同地址和端口的 sockets 所在的进程必须有同一个有效的 EUID (effective user ID)。这个限制主要是用于多进程场景的,因为同一个进程内的多线程共用进程的那一个 EUID,也就是说,如果一个进程使用了 SO_REUSEPORT 监听了某个地址和端口,第二个进程如果也要监听相同的地址和端口的话,那么这个进程必须要有和上一个进程相同的 EUID,EUID 和 RUID (real user ID) 通常是一样的,但可临时修改用于给无权限的用户授权,这部分是 Linux 进程调度的基础知识,如果不了解的读者请自行学习,这里不再赘述。简单来说,这个限制的主要目的就是要求所有监听同一个地址和端口的进程都必须是属于同一个用户的,防止不同用户进行端口劫持,“偷"网络流量。具体的实现可以看最初的内核 commit。
SO_REUSEPORT 的连接迁移问题 #
上面描述的 SO_REUSEPORT 第二个问题在无状态服务 (比如大多数的互联网服务) 中的影响通常不大,连接被丢弃无所谓,让客户端重连即可。但是在有状态服务 (比如游戏,直播等) 中可就生死攸关了,这种场景中,不仅要应对实例的意外退出导致的连接被丢弃的问题,而且还有服务进行自我负载均衡从而主动迁移当前实例上的连接到另外的实例,这个时候,如果服务一开始就使用了 SO_REUSEPORT 来提升网络性能的话,连接的迁移就会变得非常棘手。
这个问题在 Linux 第一版的 SO_REUSEPORT 实现中是不支持的,因为连接迁移的实现比较复杂,本质上是因为 TCP 连接的三次握手18:完成三次握手的连接会被放到对应 listening socket 的 accept queue,这些连接相对来说比较容易进行迁移,只需要直接从一个 listening socket 的 accept queue 移到另外一个就行了,真正麻烦的是那些还处于三次握手流程中的连接,内核如果要迁移这些连接的话就只能等它们完成三次握手,或者第二次握手的 SYN+ACK 重发的时候,也就是连接要么已经进入 accept queue、要么已经进入 SYN queue。总而言之,迁移过程中旧进程中的 listening socket 的连接必须要在内核里停留足够长的时间直到完成三次握手,这对内核来说有点复杂。
虽然实现复杂,但是内核后来还是陆陆续续提交了一些 patches 修复了这个问题,我们先来介绍一下主动迁移的场景,看看有哪些方法可以实现 SO_REUSEPORT 下的连接迁移。
首先是用户空间的方法:
- 最简单的方法就是用户程序自己手动迁移,使用
SO_REUSEPORT创建一个新的 listening socket,然后通过不断地调用accept()直至返回EAGAIN错误,也就是排空旧 listening socket 的 accept queue 中的连接,处理完之后再关闭旧的 listener。这个方法的问题是这个过程并不是原子化的,也就是说在排空旧 listener 的过程中有可能新的连接又在源源不断地进来,于是在收到EAGAIN错误和关闭 listener 的这个时间窗口内的那些还未完成三次握手的连接将被 RST 信号终止掉,从而导致丢连接。 - 另一种方式是使用 Unix domain socket 传递文件描述符,也就是利用 unix domain socket 提供的进程间传递文件描述符的功能
SCM_RIGHTS,把旧 listener 的 fd 传递到另一个进程中去,如果是要 scale-out 的话就不需要关闭旧 listener,直接两个一起用就行。但是如果是 scale-in 的话,还是要关闭旧 listener,这样的话还是有问题。关于 unix domain socket 传递文件描述符的过程和原理在《UNIX 网络编程 —— 卷一:套接字联网 API》一书中的第 15 章第 7 节中有详尽的介绍,这里便不再赘述。
接下来是基于 BPF/eBPF 的内核沙盒程序的方法,Linux 4.1919 引入了两个新的 BPF 类型 —— BPF_MAP_TYPE_REUSEPORT_SOCKARRAY 和 BPF_PROG_TYPE_SK_REUSEPORT20,利用这两个新类型的支持,开发者可以编写 BPF/eBPF 程序然后直接在内核中迁移连接,这种方式相比前面介绍的两种用户空间的方法更加彻底,通过 BPF/eBPF 我们可以在内核中运行用户的沙盒程序,直接在网络栈那一层操作 TCP 连接的迁移,创建新的 listener 加进 BPF/eBPF 的 map 里,未来的新连接就都会全部重定向到这个新的 listener 上去,然后从 map 中移除掉旧的 listener,等带连接的三次握手完成,然后在旧 listener 上调用 accept() 消费那些已完成三次握手的连接直到 EAGAIN,最后就可以安全地关闭掉旧 listener,彻底完成连接迁移。
上述都是需要用户程序手动进行迁移的方法,而且都挺复杂的,用户空间的方法就不说了,BPF/eBPF 沙盒程序这种方式对于大部分普通开发者来说有不小的学习成本和编程成本,所以 Linux 内核后来在 5.10.188 版本21中终于实现了内核自动迁移连接的功能,通过内核参数 tcp_migrate_req22 可以开启这项功能,用户通常需要使用 BPF_SK_REUSEPORT_SELECT_OR_MIGRATE 来自定义连接迁移时的策略 —— 将已关闭的 listener 中的连接迁移到哪一个新的 listener,不过不设置可以,这样的话内核就会随机选。当开启了这个功能之后,如果多个设置了 SO_REUSEPORT listeners 中某一个或多个 listener 关闭了,内核就会自动将那些已关闭的 listeners 中的连接迁移到那些还在运行的 listeners 上去。需要注意的是,开启这个功能之前要确保所有设置了 SO_REUSEPORT 并监听了同一个地址和端口的 listeners 必须有相同的设置,否则的话,开启这个功能可能会导致应用 crash,比如一部分 listeners 设置了某些会影响到连接迁移的套接字选项 (比如 TCP_SAVE_SYN),而其他的 listeners 没有设置,这就可能导致连接迁移之后出现问题。
tcp_migrate_req 默认是关闭的,这个决策是基于以下两个理由:
- 第一个原因前面已经论述过了,listener sockets 可能有不同的设置,可能导致应用崩溃。
- 第二个原因则是,开发者可能会针对 listener socket 专门编写一些 BPF/eBPF 沙盒程序,在其中定义一些 TCP 连接路由的策略,可能会与
tcp_migrate_req功能相冲突。
这个内核功能一开始有一些质疑,有人反馈说自 Linux 推出 SO_REUSEPORT 之后,accept() 系统调用已经被重构成无锁的实现了,也就是说多线程共享一个 TCP listener 的性能应该有大幅的提升了,也许就不再需要 SO_REUSEPORT 的负载均衡功能了,使用以前的多线程共享一个 TCP listener 的模式就行了,所以这时候再引入一个这么复杂的自动迁移连接的功能可能没有多大的必要。话虽如此,但是就我查询到的一些关于 SO_REUSEPORT 的一些近期的资料都指出了这个套接字选项对 accept() 的性能还是有大幅的提升,我猜就算 accept() 现在是无锁的实现,但是多线程共享一个 listener 毕竟还是有竞争,在海量连接涌入的场景下,SO_REUSEPORT 这种对网络连接进行分流的模式应该还是更有优势。
总而言之,如何进行连接迁移应该取决于用户的具体业务场景,使用用户空间的方法或者 BPF/eBPF 内核技术,抑或是全程委托给内核的自动迁移,根据我在本小节中的介绍,读者可以可以自行评估进行选择。
DragonFlyBSD #
在 Linux 实现了 SO_REUSEPORT 之后,没过多久,在同一年 (2013) DragonFlyBSD 3.623 就跟进了这个变更,扩展了已有的 SO_REUSEPORT 的语义24,使之与 Linux 相同,引入和 Linux 相同的负载均衡能力,最终使得其 accept() 的使用效率提升了 200%25。DragonFlyBSD 的 SO_REUSEPORT 实现比 Linux 的第一版实现还更为先进一些,它使用了两个哈希表来实现,而且其负载均衡策略选用了路由器的 hash-threshold26 算法而非 Linux 中简单的 modulo-N 取模,从而解决了 Linux 第一版 SO_REUSEPORT 中的丢连接的缺陷。但与此同时,也因为使用了 hash-threshold 而导致了另一个缺陷:同一个端口复用最多只支持 256 个绑定。
FreeBSD #
FreeBSD 则是在 Linux 的 SO_REUSEPORT 发布的四年后才实现了支持负载均衡的 SO_REUSEPORT 套接字选项。但是 FreeBSD 并没有仿照 DragonFlyBSD 方式直接扩展已有的 SO_REUSEPORT 语义,而是选择增加一个新的套接字选项 —— SO_REUSEPORT_LB 来支持负载均衡的功能27。之所以如此,是因为 FreeBSD 社区对 Linux 一开始就直接扩展 SO_REUSEPORT 的语义的行为颇有微词,认为 Linux 此举并没有尊重 SO_REUSEPORT 的原始语义,而且是在滥用这个套接字选项。这里能看出 FreeBSD 与 Linux 这两个操作系统在价值观和方法论方面的区别:FreeBSD 是从 BSD (Berkeley Software Distribution) 衍生而来的,BSD 原来是加州大学伯克利分校里的一群学者基于 Unix 操作系统搞出来的,后来 FreeBSD 从 BSD 脱离出来之后也有很多高校里的操作系统高手帮忙开发和维护,所以 FreeBSD 作为最正统以及目前市场份额最大的 BSD 系 OS,其社区一贯都比较偏学院派作风;而 Linux 的发迹史则更偏向一种野蛮生长的作风:一个本科生写出来的玩具 OS,然后丢到网上共享,吸引了全世界的开发者一起为其贡献代码,在轰轰烈烈的 GNU 自由软件运动的那几年中一直缺一个操作系统内核,而 GNU 自家的 Hurd 一直难产,彼时出身名门的 FreeBSD 本来应当是 GNU 内核的最佳选择,不巧的是那时候刚好赶上 AT&T 公司和 BSDi 关于 Unix 和 BSD 的版权纠纷28而被牵扯其中,错过了 GNU 缺失 OS 内核那短短的黄金数年,与此同时 Linux 抓住机会猥琐发育并最终成功上位,成为了 GNU 的首选内核,也就是现在的 GNU/Linux。因此,Linux 社区更偏向于工程派作风,方法论主要是实用主义,管你符不符合标准,好用就行!Linux 破坏 POSIX 标准的行为也不是一次两次了。
SO_REUSEPORT_LB 的实现代码基本上就是从 DragonFlyBSD 那里抄过来的,然后做了一些优化和改进而已。所以这个新的套接字选项的语义和功能基本上也就和 DragonFlyBSD 的 SO_REUSEPORT 是一致的,包括那个同一端口最多 256 个绑定的限制也一样在 SO_REUSEPORT_LB 中存在。
NetBSD & OpenBSD #
NetBSD 是从 4.3BSD 拉出来的分支29,而 OpenBSD 则是从 NetBSD 1.0 版本拉出来的分支30,BSD 系统的最后一个版本是 4.4BSD,所以 4.3BSD 已经是晚期的 BSD 版本了,因此这两个操作系统上的 SO_REUSEADDR 和 SO_REUSEPORT 的语义就是标准的 BSD 语义,和 FreeBSD 是一致的。
macOS #
macOS 的历史要更复杂一些,史蒂夫·乔布斯被踢出苹果公司之后开了一家叫 NeXT 的公司,这家公司开发了一个叫做 NeXTSTEP 的操作系统,这个操作系统的内核是一种混合内核 (hybrid kernel) —— 由微内核 (Mach) 和宏内核 (BSD) 组成而成,微内核 Mach 最早是在卡耐基梅隆大学开发的,NeXTSTEP 直接拿过来改了一下用作微内核,而宏内核 BSD 部分则是主要是从 FreeBSD 内核同步过来的代码,这个操作系统就是后来的 OSX 和 macOS 的前身。后来苹果收购 NeXT 并把乔布斯请回公司之后,将 NeXTSTEP 苹果现有的 Mac 用户环境合并起来创造了 OSX 操作系统,后来重命名为 macOS,其中的混合内核也被命名为 XNU。
因此,macOS 从用户层的视角看来就是一个 BSD 系统,因此它的 SO_REUSEADDR 和 SO_REUSEPORT 语义和实现与 FreeBSD 是一致的。有趣的是 macOS 还是为数不多的几个经过 POSIX 认证的完全符合 POSIX 标准的操作系统31。甚至连 *BSD 系列的操作系统都没一个是 POSIX 认证的,Linux 就更别说了,不遵守 POSIX 标准也不是一天两天了。
SunOS #
SunOS 最早也是源于 BSD,后来独立发展,目前的两大分支是 Solaris 和 illumos,后者不支持 SO_REUSEPORT (4 年前有人提了 issue 希望支持,但至今没有实现32),只支持 SO_REUSEADDR。而 Solaris 一直支持 SO_REUSEADDR,但是在 Solaris 11 之前并不支持 SO_REUSEPORT,Solaris 11 开始支持,但在最新的 Solaris 11.4 之前这个套接字选项和之前的 *BSD 系 OS 的语义一样,没有负载均衡的能力,而在 Solaris 11.4 中终于扩展了 SO_REUSEPORT 的语义,支持了负载均衡。Solaris 的实现应该是参考了 Linux,因为 Solaris 也为这个套接字选项引入了一个和 Linux 相同的限制:所有使用 SO_REUSEPORT 绑定同一个地址和端口的 sockets 所在的进程都必须要共享同一个 EUID。
AIX #
IBM AIX 也是一个衍生自 BSD 的操作系统,同样支持 SO_REUSEADDR 和 SO_REUSEPORT,语义相同。和其他 *BSD OS 一样,最开始 SO_REUSEPORT 并不支持负载均衡,但是在 AIX 7.2 之后实现了负载均衡的功能33,和 DragonFlyBSD 一样是通过直接扩展 SO_REUSEPORT 的语义实现的。
Windows #
Windows 上只有 SO_REUSEADDR 这个套接字选项,但是这个选项又很特殊,因为它同时具备 BSD socket 中的 SO_REUSEADDR 和 SO_REUSEPORT 两个套接字选项的特性。但是要注意的是,在 Windows 2003 以前的版本中,即便第一个 socket 没有设置 SO_REUSEADDR,只要第二个 socket 设置了 SO_REUSEADDR,就可以成功绑定第一个 socket 已经绑定的地址和端口,很明显和 BSD socket 的 SO_REUSEPORT 的语义不同,而且很显然有重大的安全隐患 —— 端口劫持。后来微软意识到了这个问题,然后引入了一个新的套接字选项 —— SO_EXCLUSIVEADDRUSE,只要第一个 socket 在绑定某个地址和端口之前设置了它,就表示该 socket 独占了这个地址和端口,那么后续所有其他的 sockets 即使设置了 SO_REUSEADDR 也无法再绑定这个地址和端口。
Windows 2003 的时候又引入了一个叫做 Enhanced Socket Security 的特性,把原先就挺混乱的 SO_REUSEADDR 和 SO_EXCLUSIVEADDRUSE 设置给搞得更加混乱了,而且不同的操作系统用户使用这些套接字选项又有不同的行为。总之,Windows 在这一块是乱成一锅粥了,建议有兴趣的读者直接参考微软的官方文档吧。
应用 #
SO_REUSEADDR 和 SO_REUSEPORT 的常规应用在前文中已经讲解过了,主要是用于重复绑定地址和端口。这里要介绍一下 Linux 破坏 SO_REUSEPORT 的原始语义而引入的负载均衡功能方面的应用。虽然是破坏了套接字选项的原始语义,但是不得不说 Linux 引入的这个负载均衡的能力确实对网络系统的性能有极大的提升,网络流量在内核空间自动进行负载均衡,最终在用户空间分流,这个能力使得用户空间的程序能够轻易地将原本的单线程 (进程) 的架构重构成多线程 (进程) 架构,从而大幅度地提升网络吞吐性能和处理效率。后端网络 I/O 的代码基本不需要修改,只需要在前端的 listener 层做一下 SO_REUSEPORT 的简单改造即可,然后 accept() 就可以在多线程 (进程) 中直接使用了,非常方便,极大地节省了代码重构的成本。
此外,SO_REUSEPORT 的负载均衡能力不仅可以用于 accept(),而且应用于 epoll、kqueue 等 I/O 多路复用技术,实现网络流量分流的功能。我之前为 Node.js、Julia 和 Luvit 等编程语言/框架的底层网络库 —— libuv 做过 TCP 和 UDP 的 SO_REUSEPORT 支持34 35 36:libuv 网络库本身是一个单线程网络模型,利用 SO_REUSEPORT 的负载均衡能力可以很轻易地将 libuv 扩展成多线程网络模型。我想,这个现实世界中的例子可以作为一点参考。
总结 #
本文地对 TCP/UDP 协议中的两个非常重要和常用的套接字选项 —— SO_REUSEADDR 和 SO_REUSEPORT 进行深入的剖析,期间涉及到的网络方面的知识可以说是面面俱到,从 TCP/UDP 的五元组讲起,然后分析 SO_REUSEADDR 和 SO_REUSEPORT 的设计初衷和使用场景,到各个不同的操作系统上对这两个套接字选项的实现细节的异同,都深入浅出地分析了一遍,相信通过这些剖析,读者可以极大地加深对 TCP/UDP 协议的理解,以及对这两种协议下的网络编程的概念和技巧都能有所启发和收获。
SO_REUSEADDR 最重要的作用就是处理 INADDR_ANY 通配地址和 TCP 的 ESTABLISHED、TIME-WAIT 状态下的地址重用问题。而 SO_REUSEPORT 最初只是 SO_REUSEADDR 的一个扩展,随着 Linux 3.9 进一步扩展了其语义引入了负载均衡的能力之后,其他的操作系统纷纷跟进了这一个功能,最终 SO_REUSEPORT 除了 BSD 最初的原始语义之外,其负载均衡的功能还成为了 TCP/UDP 标准的多线程 (进程) 网络模型的核心。
参考&延伸阅读 #
- The Sockets Networking API: UNIX® Network Programming Volume 1, Third Edition
- How do SO_REUSEADDR and SO_REUSEPORT differ?
- The SO_REUSEPORT socket option
- Avoiding unintended connection failures with SO_REUSEPORT
- Socket SO_REUSEPORT and Kernel Implementations
- Avoiding unintended connection failures with SO_REUSEPORT
- Socket migration for SO_REUSEPORT - Kuniyuki Iwashima
- Windows Sockets 2 —— Using SO_REUSEADDR and SO_EXCLUSIVEADDRUSE
listen - listen for socket connections and limit the queue of incoming connections ↩︎
socket: Extend SO_REUSEPORT to distribute workload to available sockets ↩︎
Analysis of an Equal-Cost Multi-Path Algorithm —— Hash-Threshold ↩︎
How to get the better listening performance for multiple listening sockets using the same port number via the SO_REUSEPORT ↩︎
libuv —— unix: support SO_REUSEPORT with load balancing for TCP ↩︎
libuv —— unix: support SO_REUSEPORT with load balancing for UDP ↩︎