Linux epoll 之 LT & ET 模式精粹
目录

导言 #
现代操作系统上的 I/O 多路复用技术如 epoll 和 kqueue 等通常有两种工作模式:Level-triggered (LT) 和 edge-triggered (ET) 模式,也就是水平触发和边缘触发。这两种模式在应用中有很大的区别,在实际编程中的坑点也不少,特别是后者,使用 ET 模式进行编程很容易写出 bugs。与此同时,基于 I/O 多路复用技术的程序也有很多奇技淫巧,能够用来优化代码、提升性能。
本文将深入浅出地剖析 Linux 上的 epoll 的基本原理和一些历史遗留的技术债,然后会着重介绍 epoll 在 ET 模式下的坑以及一些有用的奇技淫巧,相信对那些使用 epoll 编程的读者会有一些帮助和启发。注意,本文不是 epoll 的入门介绍文章,所以要求读者使用过 epoll 进行编程以及有一定的 epoll 编程基础。如果是完全不了解 epoll 而且希望能进行入门学习的读者,我推荐一篇写得很好的 epoll 入门文章,这一篇文章对 epoll 有一个比较全面的介绍,虽然其涉及的相关知识比较浅,但是作为入门学习的资料非常合适,即便是那些对 epoll 比较熟悉的开发者也可以读一读,我相信还是能从中收获一些东西的,至少不会空手而归。
I/O 多路复用的模式 (epoll) #
Epoll 代表的是 Event Poll,也即是事件轮询,但是 epoll 本身的原理是事件驱动 (Event-Driven),同时再结合轮询的手段。这两者的区别是:轮询是主动行为,驱动是被动行为,后面我们会逐步讲解这方面的内容。我们先来简单地看一下 epoll 的一般工作流程。
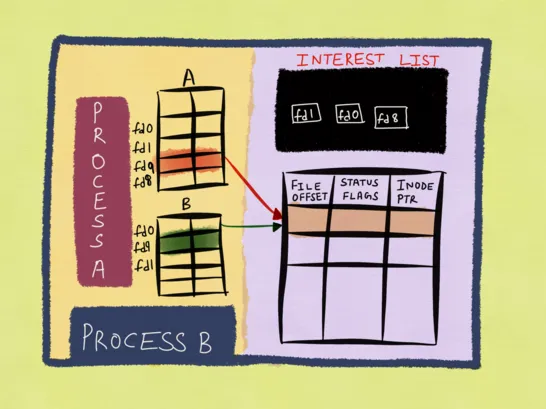
在 epoll 内部维护了三个核心的数据结构:interest list (红黑树)、wait queue (链表) 和 ready list (链表),interest list 和 ready list 是 epoll 实例级别的,wait queue 则有两种:epoll 实例级别和文件描述符级别,内核除了会为 epoll 实例维护一个全局的 wait queue,还会为 interest list 中每一个文件描述符都维护一个本地的 wait queue 用于注册文件描述符的等待事件和对应的回调函数。
我们使用 epoll 时会调用 epoll_ctl(2) ,此时内核会先将待监听的文件描述符打包成一个 epitem (epoll item) 之后插入 epoll 的 interest list,然后再将 epitem 打包进 ep_pqueue,最后将这个等待事件加进文件描述符本地的 wait queue,同时为其注册一个回调函数 ep_poll_callback()。
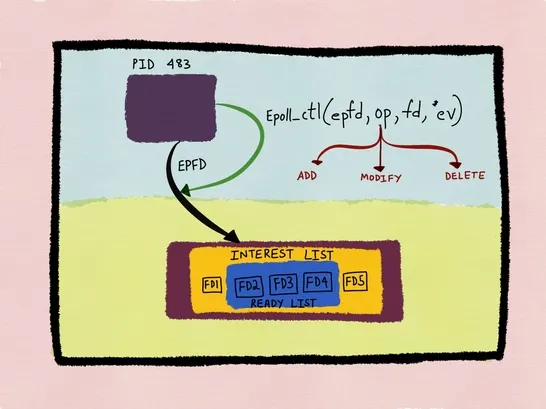
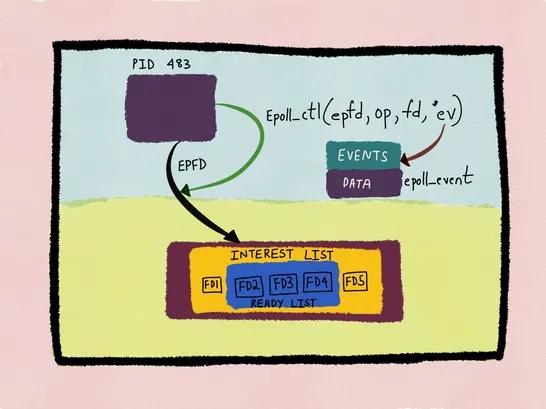
这之后就可以调用 epoll_wait(2) 等待事件了,这个系统调用会首先扫描 ready list,如果链表中有事件则返回给用户程序,否则就注册一个等待事件到 epoll 实例的 wait queue,主动把自己从当前的 CPU 调度走,保存现场并进入阻塞状态,等待就绪事件的到来。
假设我们前面注册进 epoll 的文件描述符是一个 socket,那么当网卡收到这个 socket 的网络包之后,DMA 就会将数据拷贝到内存并发出一个硬件中断通知内核,内核收到硬中断之后会调用硬中断处理程序,然后再触发一个软件中断,启动软中断处理程序,先定位到 DMA 拷贝的数据在内存中的地址,然后将其中的数据过一遍网络协议栈,按照 OSI 中每一层的特定协议逐层解包,最后得到原始的应用数据1,与此同时软中断程序会找到 socket 的 wait queue 中对应的事件回调函数 ep_poll_callback() 并调用之,将 epitem 就插入到 epoll 的 ready list 中并唤醒被阻塞在 epoll_wait(2) 系统调用的进程/线程,内核的进程调度器会重新调度这个进程,当进程被调度器选中并放到 CPU 上执行的时候,恢复现场并继续执行 epoll_wait(2) 扫描 ready list 链表取出事件返回,用户程序就可以开始处理就绪事件了。
Linux epoll 的 LT 和 ET 模式中的 Level 和 Edge 实际上是来源于电磁学中的术语,Level 代表电平,指的是电压所处的状态或水平,而 Edge 则代表信号的状态转变。在电磁学中,Level-Triggering 代表的是一种对输入信号的持续性监控机制;而 Edge-Triggering 代表的是一种对信号状态的瞬时性转变的监控机制。以二进制逻辑电平来说,如果信号电平是 1,LT 模式就会一直触发通知,直到信号电平变成 0;而 ET 模式则只会在信号电平发生转变 (0 -> 1 或者 1 -> 0) 的时候触发一次通知。
用一个例子来理解并区分 LT 和 ET 模式2:
- 创建一个 pipe,得到读写两个端的文件描述符
rfd和wfd,现在调用epoll_ctl(2)将rfd注册到 epoll 实例中,并调用epoll_wait(2)等待事件; - 往 pipe 的写端写入 2 KB 的数据;
epoll_wait(2)返回,通知调用者rfd有数据可读;- 从 pipe 读端
rfd读出 1 KB 数据; - 再次调用
epoll_wait(2)。
LT 和 ET 模式的区别就体现在第 5 步中 epoll_wait(2) 的行为:如果是 LT 模式,则 epoll_wait(2) 调用会返回,并再次通知调用者 rfd 可读;而如果是 ET 模式,该调用则会阻塞,也就是没有任何事件可以返回。
这两种不同的行为很好地表现了 LT 和 ET 在处理 I/O 事件方面的不同语义:
- LT 模式下,是否通知用户程序取决于状态。比如上面的
rfd,它还有数据没读完,所以其状态依然是"可读"readable,也就是还有 I/O 事件没处理完,那么 LT 就会一直通知,直到所有的 I/O 事件被处理完,也就是rfd中的所有数据都被读取出来了,状态变为"不可读"unreadable。 - ET 模式下,是否通知并取决于状态变化。还是以上面的
rfd为例,ET 模式下的第 3 步的epoll_wait(2)之所以会通知用户程序,就是因为 pipe 中写入了数据,所以rfd的状态从一开始的unreadble变成了readable,所以 ET 会触发通知;同理,第 5 步之所以不会触发通知,是因为自从第一次状态变化之后rfd的状态并没有再次发生转变,一开始是readable,现在还是readable,所以 ET 就不再通知了。
上面的描述是理想状态下的 LT 和 ET 语义,正如 Linus 所说的那样3:
This is literally an epoll() confusion about what an “edge” is.
An edge is not “somebody wrote more data”. An edge is “there was no data, now there is data”.
And a level triggered event is also not “somebody wrote more data”. A level-triggered signal is simply “there is data”.
Notice how neither edge nor level are about “more data”. One is about the edge of “no data” -> “some data”, and the other is just a “data is available”.
Linus 的这段话其实也道出了很多开发者对 epoll 的 LT 和 ET 模式的一般理解,我想应该有不少人在此之前一直都是默认 epoll 的工作模式就是完全符合上面描述的理想状态下的 LT 和 ET。这两个术语在 Linux 内核当年开发 epoll 技术的时候被借用过来为其支持的两种工作模式命名。然而,epoll 的 LT 模式实现和原始的 LT 语义是一致的,但是其 ET 模式实现却没有严格遵循原始的 ET 语义,我们在下文继续剖析。
Level-triggered 模式 #
LT 是 epoll 的默认模式,在这个模式下,epoll 本质上就只是一个优化版的 poll,其工作流程完全符合上文所描述的理想状态下的 LT 语义,也就是根据所监听的文件描述符的当前状态来决定是否触发通知,所以只要文件描述符处于 readable 或者 writable 状态,epoll 就会一直通知用户程序去处理,直到状态变成 unreadable 或者 unwritable。
值得一提的点是,通常我们看很多基于 epoll 网络库都会将 socket fd 设置成 non-blocking 的模式,不管是在 LT 还是 ET 模式。实际上只有在 ET 模式下才必须使用 non-blocking 非阻塞 I/O ,因为在 ET 模式不像 LT 模式,只要状态没变就会一直触发事件通知,所以很容易因为处理事件不彻底从而导致未来再也没有机会再继续处理,因此 ET 模式下一般的编程范式是要求用户程序一直读或者写 socket fd 直到返回 EAGAIN 错误,确保所有事件都处理完了,这时如果 socket fd 不是非阻塞的,则会在最后一次 read(2)/write(2) 操作中阻塞线程/进程,导致 I/O 事件循环 (event loop) 无法进行下去。
而在 LT 模式下,非阻塞文件描述符严格来说并不是必需的,当然前提是你对那些文件描述符的所有 I/O 操作全都是基于 epoll_wait(2) 所返回的指示来进行的,比如 epoll 通知你某个 socket 现在是 readable,那你可以放心地对其调用 read(2) 而不用担心会阻塞住,因为 epoll 保证一定有数据可以读出来,所以不会阻塞你的第一次 read(2) 调用。你只读一次也就行了,反正在 LT 模式下如果你没读完 socket buffer 里的所有数据,epoll 还会继续通知你去读直到所有数据都被读完,所以非阻塞 I/O 不是必需的。然而在大多数场景中还是建议使用非阻塞 I/O,即便是使用 LT 模式,因为在程序中很难保证严格按照 epoll 的指示操作,有时候需要在别的地方执行 I/O 操作 (比如一些异步任务),那么就有可能会阻塞住。
Edge-triggered 模式 #
通过 epoll_ctl(2) 注册文件描述符的时候, 设置 EPOLLET 就能开启 ET 模式。
ET 模式下,有一个至关重要的问题:开头的例子中第 5 步调用 epoll_wait(2) 时会阻塞住,按照理想的 ET 语义来解释是因为 rfd 的状态没有发生任何转变,那么如果我在另一个线程中往 wfd 再次写入 1 KB 的数据,此时阻塞中的 epoll_wait(2) 会返回吗?如果按照 ET 模式的真正语义来看,答案是否定的,因为 rfd 的状态还是没有发生变化,之前是 readable 现在还是 readable,只不过是 pipe 里的数据增多了而已。但是在 Linux 上实测是会返回的,也就是说,Linux 的 epoll ET 实现并不是真正的 Edge-Triggering,实际上也的确如此,epoll 的 ET 模式最初实现的时候就是"错的",没有严格实现 ET 的真正语义。前文陈述过,严格的 ET 语义要求只有在状态变化的时候才触发通知,而 epoll 实现的 ET 语义是只要有变化就会通知,这里的变化的范围更加广,它包含了状态变化,换言之就是语义更加宽松了,被监控的对象除了状态变化之外的任何变化都会通知,也就是前者是后者超集,后者是前者的子集,当 wfd 被再次写入数据时,rfd 的状态并没有发生变化,原先是 readable 现在还是 readable,但是 pipe 本身发生了变化 —— 数据变多了,所以 epoll 会触发一次新的通知。
我一直以为这是 Linux 有意为之,但后来看到了一些资料发现原来不是,是 epoll 在设计之初出现了失误导致了现在的 ET 行为模式。相信很多人在了解到 Linux epoll 的 ET 模式的这个坑之后都会有点不可置信,正如我自己所说:我不敢相信像 epoll 这么复杂的东西竟然从根基上就是错误的4。事实上 Linux 还因为 epoll ET 的这个问题引发过一次不小的故障:2019 年底的时候 Linux 对 pipe 进行了重构,其中有一个 Linus 提交的 commit 将 pipe 在 epoll/poll/select 中的行为模式给改了,原先的行为是只要往 pipe 的 wfd 写入数据,ET 模式下正在监控 rfd 的 epoll_wait(2) 就会触发通知事件并返回,也就是我们上面说的更为宽松的 ET 语义,但是在那个 commit 被提交进内核源码主线之后,pipe 的行为就会遵循严格的 ET 语义,也就是只有状态变化才会触发通知事件。这个改动在将近一年后被当时的 Linux 的系统手册 —— man-pages 的 maintainer —— Michael Kerrisk (他也是大名鼎鼎的 The Linux Programming Interface 一书的作者) 提出质疑并希望能恢复 pipe 的旧行为,因为这个变更可能会导致一些已经依赖了 pipe 这种旧行为的代码无法正常工作。
果不其然,不久后 Android 12 beta 发布,其中一些依赖库如 Realm 真的利用了 pipe 在 epoll ET 下的这种行为对系统进行优化:在 pipe 中已经有了数据的情况下收到通知之后一直不读,等到最后一次 epoll ET 通知才一次性读完所有数据。然而在内核修改成严格的 ET 语义之后,第一次通知不处理的话,后面即便再往 pipe 里写入数据也不会再发新的通知了,导致这个库运行异常,连带着搞挂了 Android 12 beta 系统上的很多应用,虽然后来 Realm 紧急修复了这个问题,但根源还是在 Linux 内核,除了 Realm 可能还有很多其他的库和系统也依赖了 pipe 宽松的 ET 语义;最后,Linux 决定恢复 pipe 的旧行为并提交了两个 commits 5 6,以此修复这个故障7。
虽然搞了一个大事故,不过塞翁失马焉知非福,epoll ET 的宽松语义反而在某些方面会比严格的语义更具备优势,我们后面接着分析。
使用 ET 模式编程时也有一个值得一提的点,收到就绪事件通知之后,通常的模式是调用 read(2)/write(2) 直到返回 EAGAIN,这是使用 ET 模式时的通用模式,但是对于基于(字节)流的 (stream-oriented) 文件类型 (比如基于流的 socket:TCP socket 或者 Unix Domain socket 等,以及 pipe、FIFO 等) 来说还有一个可优化的地方:如果连续调用 read(2)/write(2) 时的返回值小于请求的字节长度,则可以断定文件描述符里当前可读/写的数据量少于请求量,那么就可以不用再调用了,因为下一次一定会返回 EAGAIN,节省一次系统调用。注意这个优化手段仅限于基于流的文件描述符,对于其他的文件类型,比如基于数据报或者字符的文件类型 —— UDP socket、字符设备比如终端等,EAGAIN 错误是唯一的方式可以确定数据读完或者写不进了,所以无法应用这种优化手段。
不过,我感觉 epoll 的 man page2 和 read(2) 的 man page8 有一点自相矛盾,因为根据后者,在 Linux 中除了上面提到的"文件描述符里当前可读的数据量少于请求量",以下几种情况也可能会导致 read(2) 返回的字节数少于请求读的字节数:
- 快到文件尾 (EOF, end-of-file) 了
- 请求读的字节数超过 Linux 的限制
read(2)被信号中断了- 文件描述符是 pipe
- 文件描述符是终端 (terminal)
第一个 EOF 不算什么问题,因为通常内核只能知晓那些可以对其调用 lseek(2) 的文件类型 (比如磁盘文件) 的 EOF,而 epoll 本来也不支持那部分类型的文件比如磁盘文件 (Linux 提供了另外的子系统 inotify 来监听文件系统),epoll 主要用于 socket、pipe、FIFO 这一类不支持 lseek(2) 的文件类型,而这些类型的文件描述符的 EOF 代表的是对端关闭,内核也不可能知道这些文件描述符"快到" EOF 了,因为内核只可能知道对端已经关闭了,而不可能知道对端快要关闭了。第二个通常也不会出现,Linux read(2) (其他 I/O 系统调用同理) 支持最多一次性传输 0x7ffff000 (2,147,479,552) 字节数的数据,也就是 2 GB 减去 4 KB,读写 socket、pipe、FIFO 的时候一般不可能一次性操作这么大的数据量,因为不管是底层的 socket buffer 还是 pipe buffer 都远远小于这个限制。第三种情况通常会返回一个 EINTR 错误,而 man page 里明确说了如果返回了这个这个错误,说明没有数据会被读取,但是信号中断通常发生于阻塞操作,non-blocking I/O 应该不会返回这个错误9,而 non-blocking I/O 通常是使用 epoll 时的标配,所以也不成问题。
真正可能有问题的是最后两种,也就是操作 pipe 和 terminal 这两种类型的文件,“不幸"的是,epoll 还真就支持这两种文件类型。从 man page 来看,对这两种文件描述符调用 read(2) 时就算其中有足够的数据也可能会返回少于请求的数据量8,这里应该指的是请求读取的数据量超过了文件类型本身的 capacity,比如 pipe 的大小通常是 16 KB,所以如果使用 epoll 管理文件描述符中包含了这两类,那我建议还是老老实实地用 EAGAIN 这种方式吧!
内核中的 LT & ET #
前面说过 epoll 的本质是事件驱动+事件轮询,前者主要依靠内核的 callback + wakeup 机制来实现,也就是回调+唤醒的机制;后者则比较简单,轮询,也即是反复查询,这里的轮询主要针对的是 ready list。而 LT 和 ET 模式在实现上的差异也主要集中在这两个地方,因此,我们主要来看看 epoll_ctl(2) 和 epoll_wait(2) 在内核中的实现,其中最重要的两个函数就是 ep_poll_callback() 和 ep_poll()。
我们先来看一下 ep_poll_callback()10:
#define EP_PRIVATE_BITS (EPOLLWAKEUP | EPOLLONESHOT | EPOLLET | EPOLLEXCLUSIVE)
static int ep_poll_callback(wait_queue_entry_t *wait, unsigned mode, int sync, void *key)
{
int pwake = 0;
struct epitem *epi = ep_item_from_wait(wait);
struct eventpoll *ep = epi->ep;
__poll_t pollflags = key_to_poll(key);
unsigned long flags;
int ewake = 0;
// 先拿锁再进一步操作
read_lock_irqsave(&ep->lock, flags);
ep_set_busy_poll_napi_id(epi);
/*
* If the event mask does not contain any poll(2) event, we consider the
* descriptor to be disabled. This condition is likely the effect of the
* EPOLLONESHOT bit that disables the descriptor when an event is received,
* until the next EPOLL_CTL_MOD will be issued.
*/
// 只有 EP_PRIVATE_BITS 这些私有事件,对用户程序没用,直接解锁返回
if (!(epi->event.events & ~EP_PRIVATE_BITS))
goto out_unlock;
/*
* Check the events coming with the callback. At this stage, not
* every device reports the events in the "key" parameter of the
* callback. We need to be able to handle both cases here, hence the
* test for "key" != NULL before the event match test.
*/
// 就绪事件中不是用户程序关注的,也是直接解锁返回
if (pollflags && !(pollflags & epi->event.events))
goto out_unlock;
/*
* If we are transferring events to userspace, we can hold no locks
* (because we're accessing user memory, and because of linux f_op->poll()
* semantics). All the events that happen during that period of time are
* chained in ep->ovflist and requeued later on.
*/
// 当前有其他进程/线程正在调用 epoll_wait(2) 遍历 ready list,
// 那么就先把就绪的 epitem 缓存到 ep->ovflist
if (READ_ONCE(ep->ovflist) != EP_UNACTIVE_PTR) {
if (chain_epi_lockless(epi))
ep_pm_stay_awake_rcu(epi);
} else if (!ep_is_linked(epi)) { // 否则的话,检查这个 epitem 是否已经在 ready list 中, 如果没有的话就将其插进去
/* In the usual case, add event to ready list. */
if (list_add_tail_lockless(&epi->rdllink, &ep->rdllist))
// list_add_tail_lockless() 如果返回 false 则说明刚好有另一个 CPU 把这个 epitem
// 加进 ready list 中,返回 true 说明 epitem 是全新的,那么就要通知电源管理核心,
// 让其不要进入休眠,通常 Android 设备会比较常用
ep_pm_stay_awake_rcu(epi);
}
/*
* Wake up ( if active ) both the eventpoll wait list and the ->poll()
* wait list.
*/
// 检查 epoll 的 wait queue: ep->wq,如果不为空说明当前有阻塞在 epoll_wait(2)
// 的进程/线程,唤醒它们去轮询 ready list
if (waitqueue_active(&ep->wq)) {
if ((epi->event.events & EPOLLEXCLUSIVE) &&
!(pollflags & POLLFREE)) {
switch (pollflags & EPOLLINOUT_BITS) {
case EPOLLIN:
if (epi->event.events & EPOLLIN)
ewake = 1;
break;
case EPOLLOUT:
if (epi->event.events & EPOLLOUT)
ewake = 1;
break;
case 0:
ewake = 1;
break;
}
}
wake_up(&ep->wq);
}
// 这是其他的 wait queue,如果不为空说明当前有阻塞在 file->poll()
// 的进程/线程,通常是另一个 epoll fd 的 wait queue,同样需要唤醒它们
if (waitqueue_active(&ep->poll_wait))
pwake++;
out_unlock:
read_unlock_irqrestore(&ep->lock, flags);
/* We have to call this outside the lock */
if (pwake)
ep_poll_safewake(ep, epi, pollflags & EPOLL_URING_WAKE);
if (!(epi->event.events & EPOLLEXCLUSIVE))
ewake = 1;
if (pollflags & POLLFREE) {
/*
* If we race with ep_remove_wait_queue() it can miss
* ->whead = NULL and do another remove_wait_queue() after
* us, so we can't use __remove_wait_queue().
*/
list_del_init(&wait->entry);
/*
* ->whead != NULL protects us from the race with
* ep_clear_and_put() or ep_remove(), ep_remove_wait_queue()
* takes whead->lock held by the caller. Once we nullify it,
* nothing protects ep/epi or even wait.
*/
smp_store_release(&ep_pwq_from_wait(wait)->whead, NULL);
}
return ewake;
}
正如前文所述,用户程序调用 epoll_ctl(2) 注册文件描述符的时候内核会为其注册一个 ep_poll_callback() 回调函数。这个回调函数正是 epoll 的事件驱动机制的关键,当文件描述符上有事件发生时,总会有一种机制来调用这个函数,通知阻塞在 epoll_wait(2) 系统调用的进程/线程。前面也已经介绍过 socket 的例子,网卡收到数据之后会由 DMA 触发硬中断,然后调用硬中断处理程序通知内核,紧接着再触发一个软中断,进入软中断处理程序,从 socket 的本地 wait queue 中找到对应的 ep_poll_callback() 并调用,将就绪的 socket 插入 ready list 并唤醒阻塞在 epoll_wait(2) 系统调用的进程/线程去轮询 ready list 取回就绪事件并处理。这就是 epoll 的 callback + wakeup 机制。
如果说 ep_poll_callback() 里还有什么值得一提的,可能就是 ep_pm_stay_awake_rcu() 这个函数了,底层会调用 __pm_stay_awake(),它的主要作用是通知电源管理核心 (Power Management core, PMcore),不要让系统进入休眠,这个函数位于电源驱动层,Android 设备会比较常用,因为 Android 的电源管理机制和 Linux 不太一样,前者会利用休眠机制来实现设备待机,修改了 Linux 的休眠&唤醒流程。这个函数是在 list_add_tail_lockless() 返回 true 之后调用的,true 就表示这个 epitem 并没有在 ready list 中,是全新的就绪事件,Android 内核通常不希望系统在此时休眠,所以做了一套唤醒事件的机制 (System wakeup events framework) 来处理这一类的唤醒事件,其中维护了一些唤醒源的原子计数,这个 __pm_stay_awake() 就是其中的一环。
接下来让我们再来分析一下 epoll_wait(2) 的整个过程,先是系统调用的入口10:
SYSCALL_DEFINE4(epoll_wait, int, epfd, struct epoll_event __user *, events,
int, maxevents, int, timeout)
{
struct timespec64 to;
return do_epoll_wait(epfd, events, maxevents,
ep_timeout_to_timespec(&to, timeout));
}
static int do_epoll_wait(int epfd, struct epoll_event __user *events,
int maxevents, struct timespec64 *to)
{
int error;
struct fd f;
struct eventpoll *ep;
/* The maximum number of event must be greater than zero */
if (maxevents <= 0 || maxevents > EP_MAX_EVENTS)
return -EINVAL;
/* Verify that the area passed by the user is writeable */
if (!access_ok(events, maxevents * sizeof(struct epoll_event)))
return -EFAULT;
/* Get the "struct file *" for the eventpoll file */
f = fdget(epfd);
if (!f.file)
return -EBADF;
/*
* We have to check that the file structure underneath the fd
* the user passed to us _is_ an eventpoll file.
*/
error = -EINVAL;
if (!is_file_epoll(f.file))
goto error_fput;
/*
* At this point it is safe to assume that the "private_data" contains
* our own data structure.
*/
ep = f.file->private_data;
/* Time to fish for events ... */
// 核心函数,内含 epoll_wait(2) 的主逻辑
error = ep_poll(ep, events, maxevents, to);
error_fput:
fdput(f);
return error;
}
static const struct file_operations eventpoll_fops;
static inline int is_file_epoll(struct file *f)
{
return f->f_op == &eventpoll_fops;
}
static const struct file_operations eventpoll_fops = {
#ifdef CONFIG_PROC_FS
.show_fdinfo = ep_show_fdinfo,
#endif
.release = ep_eventpoll_release,
.poll = ep_eventpoll_poll,
.llseek = noop_llseek,
.unlocked_ioctl = ep_eventpoll_ioctl,
.compat_ioctl = compat_ptr_ioctl,
};
这部分源码中内核的注释已经写得很清晰了,用户程序调用 epoll_wait(2) 之后在内核中的主要流程是:
- 调用
fdget()在进程的打开文件描述符表 (open file descriptor table) 中根据 epoll fd 获取到 file 对象,这是内核执行 I/O 操作的基本对象; - 调用
is_file_epoll()检查 epoll fd 是否代表了一个真正的 epoll 实例,这是通过检查 file 对象的file_operations是否被指定了eventpoll_fops,这个结构体对象是 epoll 的操作函数表,如果读过我以前的这篇文章应该对这个结构体不陌生,它是调用epoll_create(2)创建 epoll 实例时为其指定的; - 从文件对象的
private_data(这是 file 对象的私有数据区域,通常用来存一些特定的数据) 中取出 epoll 实例,并调用ep_poll()。
ep_poll() 函数是核心,我们来看看它的代码实现,这里我尽量将内核的源码精简一下10 11 12 13:
static int ep_poll(struct eventpoll *ep, struct epoll_event __user *events,
int maxevents, struct timespec64 *timeout)
{
int res, eavail, timed_out = 0;
u64 slack = 0;
wait_queue_entry_t wait;
ktime_t expires, *to = NULL;
lockdep_assert_irqs_enabled();
// 处理用户程序指定的超时时间,主要是将 timespec 类型转换成内部使用的 ktime_t
if (timeout && (timeout->tv_sec | timeout->tv_nsec)) {
slack = select_estimate_accuracy(timeout);
to = &expires;
*to = timespec64_to_ktime(*timeout);
} else if (timeout) {
/*
* Avoid the unnecessary trip to the wait queue loop, if the
* caller specified a non blocking operation.
*/
timed_out = 1;
}
/*
* This call is racy: We may or may not see events that are being added
* to the ready list under the lock (e.g., in IRQ callbacks). For cases
* with a non-zero timeout, this thread will check the ready list under
* lock and will add to the wait queue. For cases with a zero
* timeout, the user by definition should not care and will have to
* recheck again.
*/
// 检查 ready list 和 ep->ovflist 中是否有事件,ovflist 是一个单链表,用来缓存
// ready list 被遍历期间新增的就绪事件,内核处理完 ready list 之后会把 ovflist
// 中的事件转移到 ready list 中去
eavail = ep_events_available(ep);
while (1) {
if (eavail) {
/*
* Try to transfer events to user space. In case we get
* 0 events and there's still timeout left over, we go
* trying again in search of more luck.
*/
// 轮询 ready list 并将就绪事件发送到用户空间
res = ep_send_events(ep, events, maxevents);
if (res)
return res;
}
...
eavail = ep_events_available(ep);
if (!eavail)
// 当前没有就绪事件,为当前进程创建一个等待事件并放入 epoll 实例的
// wait queue: ep->wq,等待被 ep_poll_callback() 唤醒
__add_wait_queue_exclusive(&ep->wq, &wait);
write_unlock_irq(&ep->lock);
if (!eavail)
// 当前没有就绪事件,主动让出 CPU 进入休眠并设置一个定时器
// 根据用户程序传入的值设置超时时间,时间一到就会被调度器唤醒
timed_out = !schedule_hrtimeout_range(to, slack,
HRTIMER_MODE_ABS);
// 这里的 TASK_RUNNING 表示可运行状态,而不是正在运行
__set_current_state(TASK_RUNNING);
...
}
}
// 事件轮询的主函数
static int ep_send_events(struct eventpoll *ep,
struct epoll_event __user *events, int maxevents)
{
struct epitem *epi, *tmp;
LIST_HEAD(txlist);
poll_table pt;
int res = 0;
...
// 将 poll_table 中回调函数置空,这一步需要注意,我们调用 epoll_ctl(2) 时
// 同样需要执行 init_poll_funcptr(),但那里是设置为 ep_ptable_queue_proc(),
// 然后在 ep_item_poll() 里执行,这个函数会为文件描述符的 wait queue 初始化一个
// 新的等待事件并注册回调函数 ep_poll_callback(),而这里仅仅是要用 ep_item_poll()
// 取回事件,所以回调函数置空即可
init_poll_funcptr(&pt, NULL);
// 遍历 ready list 前需要加锁,确保在遍历过程中 epoll 实例中的对象
// 不会被删除
mutex_lock(&ep->mtx);
// 前置操作,将 epoll 实例的 ready list 中的数据转移到 txlist 中,
// 这个函数调用过后 ep->rdllink 会被清空
ep_start_scan(ep, &txlist);
/*
* We can loop without lock because we are passed a task private list.
* Items cannot vanish during the loop we are holding ep->mtx.
*/
// 遍历 ready list
list_for_each_entry_safe(epi, tmp, &txlist, rdllink) {
...
/*
* If the event mask intersect the caller-requested one,
* deliver the event to userspace. Again, we are holding ep->mtx,
* so no operations coming from userspace can change the item.
*/
// 取回就绪事件,ep_poll_callback() 只是通知有"就绪事件",但是并没有
// 告知具体是哪些事件就绪了,比如是可读事件还是可写事件,所以这里需要调用
// ep_item_poll() 来检查并设置具体的就绪事件
revents = ep_item_poll(epi, &pt, 1);
if (!revents)
continue;
// 将就绪事件和数据拷贝回用户空间
events = epoll_put_uevent(revents, epi->event.data, events);
if (!events) {
list_add(&epi->rdllink, &txlist);
ep_pm_stay_awake(epi);
if (!res)
res = -EFAULT;
break;
}
res++;
if (epi->event.events & EPOLLONESHOT)
// 监听的文件描述符设置了 EPOLLONESHOT,说明是一次性通知,
// 所以此次通知之后就清空监听的事件,下次不再通知
epi->event.events &= EP_PRIVATE_BITS;
else if (!(epi->event.events & EPOLLET)) {
/*
* If this file has been added with Level
* Trigger mode, we need to insert back inside
* the ready list, so that the next call to
* epoll_wait() will check again the events
* availability. At this point, no one can insert
* into ep->rdllist besides us. The epoll_ctl()
* callers are locked out by
* ep_send_events() holding "mtx" and the
* poll callback will queue them in ep->ovflist.
*/
// !!! 区分 LT 和 ET 模式最关键的一步,如果文件描述符没有设置
// EPOLLET,说明是默认的 LT 模式,那么就将已经从 ready list
// 消费掉的 epitem 重新放回 ready list,下次用户程序调用
// epoll_wait(2) 时内核再调用 ep_item_poll() 检查它是否还没
// 处理完毕,如果是就再次返回给用户程序去处理
list_add_tail(&epi->rdllink, &ep->rdllist);
ep_pm_stay_awake(epi);
}
}
// 后置操作,在遍历 ready list 期间新增的事件会统一存放到 ep->ovflist,
// 这个函数主要是将这些事件转移到 ready list 以备下次使用
ep_done_scan(ep, &txlist);
mutex_unlock(&ep->mtx);
return res;
}
static __poll_t ep_item_poll(const struct epitem *epi, poll_table *pt,
int depth)
{
struct file *file = epi_fget(epi);
__poll_t res;
/*
* We could return EPOLLERR | EPOLLHUP or something, but let's
* treat this more as "file doesn't exist, poll didn't happen".
*/
if (!file)
return 0;
pt->_key = epi->event.events;
if (!is_file_epoll(file))
// 非 epoll fd,也就是除了 epoll 类型之外的所有的文件描述符,
// 调用通用的 vfs_poll() 进行处理
res = vfs_poll(file, pt);
else // epoll 嵌套,也就是 epoll 实例监听了另一个 epoll 实例
res = __ep_eventpoll_poll(file, pt, depth);
fput(file);
return res & epi->event.events;
}
static inline __poll_t vfs_poll(struct file *file, struct poll_table_struct *pt)
{
if (unlikely(!file->f_op->poll))
return DEFAULT_POLLMASK;
// f_op 即是 file_operations,这里假设 file 代表的是一个 socket,
// 那么 f_op 就是 socket_file_ops,f_op->poll 实际指向 sock_poll()
return file->f_op->poll(file, pt);
}
static const struct file_operations socket_file_ops = {
.owner = THIS_MODULE,
.llseek = no_llseek,
.read_iter = sock_read_iter,
.write_iter = sock_write_iter,
.poll = sock_poll,
.unlocked_ioctl = sock_ioctl,
#ifdef CONFIG_COMPAT
.compat_ioctl = compat_sock_ioctl,
#endif
.uring_cmd = io_uring_cmd_sock,
.mmap = sock_mmap,
.release = sock_close,
.fasync = sock_fasync,
.splice_write = splice_to_socket,
.splice_read = sock_splice_read,
.splice_eof = sock_splice_eof,
.show_fdinfo = sock_show_fdinfo,
};
static __poll_t sock_poll(struct file *file, poll_table *wait)
{
struct socket *sock = file->private_data;
const struct proto_ops *ops = READ_ONCE(sock->ops);
__poll_t events = poll_requested_events(wait), flag = 0;
if (!ops->poll)
return 0;
if (sk_can_busy_loop(sock->sk)) {
/* poll once if requested by the syscall */
if (events & POLL_BUSY_LOOP)
sk_busy_loop(sock->sk, 1);
/* if this socket can poll_ll, tell the system call */
flag = POLL_BUSY_LOOP;
}
// ops 的类型是 proto_ops,代表的是网络协议的操作函数表,
// 如果是 TCP 则指向 inet_stream_ops,那么 ops->poll
// 实际指向的就是 tcp_poll()
return ops->poll(file, sock, wait) | flag;
}
const struct proto_ops inet_stream_ops = {
.family = PF_INET,
.owner = THIS_MODULE,
.release = inet_release,
.bind = inet_bind,
.connect = inet_stream_connect,
.socketpair = sock_no_socketpair,
.accept = inet_accept,
.getname = inet_getname,
.poll = tcp_poll,
.ioctl = inet_ioctl,
.gettstamp = sock_gettstamp,
.listen = inet_listen,
.shutdown = inet_shutdown,
.setsockopt = sock_common_setsockopt,
.getsockopt = sock_common_getsockopt,
.sendmsg = inet_sendmsg,
.recvmsg = inet_recvmsg,
...
};
__poll_t tcp_poll(struct file *file, struct socket *sock, poll_table *wait)
{
__poll_t mask;
struct sock *sk = sock->sk;
const struct tcp_sock *tp = tcp_sk(sk);
u8 shutdown;
int state;
// 向 wait queue 中新增等待事件并注册 poll_table 中设置的回调函数,
// 注意,只有在使用 epoll_ctl(2) 注册新的监听 fd 的时候 wait->_qproc
// 才不为空并会注册回调函数。现在是 epoll_wait(2),所以 sock_poll_wait()
// 不做任何事
sock_poll_wait(file, sock, wait);
state = inet_sk_state_load(sk);
if (state == TCP_LISTEN)
return inet_csk_listen_poll(sk);
mask = 0;
// 下面这一大坨代码本质上就是进行各种条件检查,检查 socket 上现在有哪些就绪事件,
// 比如可读事件就设置 EPOLLIN,可写事件就设置 EPOLLOUT,以此类推,最后将这些
// 就绪事件返回去处理
shutdown = READ_ONCE(sk->sk_shutdown);
if (shutdown == SHUTDOWN_MASK || state == TCP_CLOSE)
mask |= EPOLLHUP;
if (shutdown & RCV_SHUTDOWN)
mask |= EPOLLIN | EPOLLRDNORM | EPOLLRDHUP;
/* Connected or passive Fast Open socket? */
if (state != TCP_SYN_SENT &&
(state != TCP_SYN_RECV || rcu_access_pointer(tp->fastopen_rsk))) {
int target = sock_rcvlowat(sk, 0, INT_MAX);
u16 urg_data = READ_ONCE(tp->urg_data);
if (unlikely(urg_data) &&
READ_ONCE(tp->urg_seq) == READ_ONCE(tp->copied_seq) &&
!sock_flag(sk, SOCK_URGINLINE))
target++;
if (tcp_stream_is_readable(sk, target))
mask |= EPOLLIN | EPOLLRDNORM;
if (!(shutdown & SEND_SHUTDOWN)) {
if (__sk_stream_is_writeable(sk, 1)) {
mask |= EPOLLOUT | EPOLLWRNORM;
} else { /* send SIGIO later */
sk_set_bit(SOCKWQ_ASYNC_NOSPACE, sk);
set_bit(SOCK_NOSPACE, &sk->sk_socket->flags);
/* Race breaker. If space is freed after
* wspace test but before the flags are set,
* IO signal will be lost. Memory barrier
* pairs with the input side.
*/
smp_mb__after_atomic();
if (__sk_stream_is_writeable(sk, 1))
mask |= EPOLLOUT | EPOLLWRNORM;
}
} else
mask |= EPOLLOUT | EPOLLWRNORM;
if (urg_data & TCP_URG_VALID)
mask |= EPOLLPRI;
} else if (state == TCP_SYN_SENT &&
inet_test_bit(DEFER_CONNECT, sk)) {
/* Active TCP fastopen socket with defer_connect
* Return EPOLLOUT so application can call write()
* in order for kernel to generate SYN+data
*/
mask |= EPOLLOUT | EPOLLWRNORM;
}
...
return mask;
}
EXPORT_SYMBOL(tcp_poll);
总的来说,epoll_wait(2) 的核心逻辑就是轮询 ready list,如果非空则直接返回数据到用户空间,否则的话就为当前进程/线程构建一个等待事件并放入 epoll 实例的 wait queue,主动让出 CPU 进入休眠,同时根据用户程序传入的 timeout 设置一个定时器,时间到了就会自动唤醒。这里我们重点关注的是事件轮询这部分的逻辑,这是区分 LT 和 ET 的关键部分。
这里的核心函数是 ep_send_events(),它会先调用 ep_start_scan() 将 ep->rdllink 中的数据转移到函数的本地链表 txlist 中 (这一步主要是为了避免加锁遍历),然后轮询这个 ready list,如果就绪链表非空则获取其中的就绪事件并返回到用户空间。其中的核心函数是 ep_item_poll(),它在这里就只做一件事:调用 vfs_poll(),而 vfs_poll() 的主要作用有二,一是检查并设置文件描述符上的就绪事件(到 epitem 中),二是调用 poll_table->_qproc 这个回调函数,后者是 epoll_ctl(2) 用来为 socket 注册 ep_poll_callback() 回调的,因为我们现在是处于 epoll_wait(2) 的逻辑中所以并不需要,因此将该回调函数置空。看到 vfs_ 这个前缀,同样地,如果读过我以前的这篇文章,应该就知道这又是一个内核提供的 VFS 通用函数,其中大概率是调用 file_operations 这个函数操作表中某一个特定的函数指针,这里调用的是 poll(),而在内核中 socket 类型的具体 file_operations 是 socket_file_ops,其中 poll() 的具体实现是 sock_poll(),这个函数又会根据不同网络协议来决定使用哪一个 proto_ops 函数操作表,如果是 TCP 的话则使用 inet_stream_ops,此时 poll() 的真正实现就是 tcp_poll(),在这个函数里内核会进行各种条件检查,判定当前这个 socket 上是否有就绪事件可以返回给用户程序去处理,也就是我们熟知的 EPOLLIN | EPOLLOUT | EPOLLERR | EPOLLHUB | ...。
如果 ep_item_poll() 的返回值是大于 0,则说明当前的 socket 有就绪事件需要处理,内核就会将其对应的 epitem (此时具体的就绪事件类型已经设置完成) 拷贝到用户空间,之后区分 LT 和 ET 模式最关键的一步就是决定是否把已经拷贝到用户空间的 epitem 重新加回到 epoll 实例的全局 ready list (也即是 ep->rdllink) 中,LT 模式下就会将 epitem 加回去,ET 模式则不会。所以下一次用户程序调用 epoll_wait(2) 时,LT 模式下会再次从 ready list 中遍历到上次那个 epitem,然后再调用 ep_item_poll() 检查该 epitem 上是否还有就绪事件,如果有则继续返回给用户程序,如果没有则忽略;而 ET 模式则没有机会再遍历到上次那个 epitem 了,因为 ep->rdllink 中此时已经没有这个 epitem 了,除非这个对应的 socket 上又有新的事件发生,启动中断处理程序并调用 ep_poll_callback() 再将其 epitem 插入 ep->rdllink。
因此,epoll 的 LT 和 ET 模式在内核中的实现共享了所有代码,LT 模式相比 ET 模式就只是多了几行代码,这几行代码的作用也仅仅是把消费过的 epitem 重新加回 ready list,却最终导致了两种模式下 epoll 行为的巨大差异。
ET 模式妙用 #
从理论上讲,ET 模式相较于 LT 模式会有性能优势,这主要体现在 ET 模式下所需的系统调用更少以及同一个系统调用的开销更小。ET 模式在理论上比 LT 模式更高效的主要原因可以归纳为如下:
epoll_ctl(2)系统调用的次数更少。epoll_wait(2)系统调用的次数更少。epoll_wait(2)系统调用内部的主动轮询次数更少。
第一个原因我们以网络编程中的 socket 来举例:如果使用 LT 模式,一般的编程范式是先将 socket 设置为非阻塞,然后调用一次 epoll_ctl(2) 为每一个 socket 注册一个 EPOLLIN,然后等待 readable 可读事件,数据来了之后触发事件,但通常只会调用 read(2) 先读取其中的一部分因为只要还有数据没读完 LT 模式就会一直通知,不怕有遗留的数据忘记读。之后回写数据到 socket 中的时候调用 write(2),如果一次性不能写完 (socket send buffer 满了) 则需要再调用一次 epoll_ctl(2) 注册一个 EPOLLOUT,等内核把 socket send buffer 的数据读走之后通知我们。同理,只要是 socket 处于 writable 可写状态,那么 LT 模式就会一直通知,所以不用怕忘记写,而当我们已经没有数据要发送的时,需要再调用一次 epoll_ctl(2) 移除 EPOLLOUT 事件,避免 epoll 未来反复触发 writable 事件。
而如果使用 ET 模式,通常的编程范式则是先将 socket 设置为非阻塞,然后调用一次 epoll_ctl(2) 为每一个 socket 一次性注册 EPOLLIN 和 EPOLLOUT 两个事件,之后来了 readable 事件,则一直调用 read(2) 把所有数据都读取出来,直到返回 EAGAIN 错误。回写数据到 socket 时,也是一直调用 write(2) 直到返回 EAGAIN 错误。之所以如此,是因为 ET 模式只在 socket 发生变化的时候才会触发通知,所以用户程序如果不及时处理完所有的数据则可能再也没有机会处理,从而导致数据永远都是不完整的。
从以上的描述不难看出 ET 模式比 LT 要少很多 epoll_ctl(2) 调用,特别是在 socket 数量特别多的情况下 (也就是 ready list 特别长的时候)。与此同时,epoll_wait(2) 的唤醒次数也会更少,因为 LT 模式每次只处理一部分数据,所以需要更多次的 epoll_wait(2) 唤醒,而 ET 则是一次性处理完所有数据,epoll_wait(2) 唤醒次数自然就更少了,这是第二个原因的解释。
第三个原因则更加直观,同一个 epoll_wait(2) 调用,如果是 LT 模式的话,在 ready list 特别长而且大部分 epitem 上都没有就绪事件的情况下,内核遍历这个链表的时候其实会做很多无用功,因为 LT 模式会无条件地将消费过的 epitem 重新加回 ready list,这样会导致内核每次遍历这个链表时重复地对那些已经没有就绪事件的 epitem 调用 ep_item_poll() 执行检查,增加了很多无谓的系统开销。而 ET 模式则完全依赖于 callback + wakeup 机制,只有在发生新的就绪事件时其对应的 epitem 才会被重新插入 ready list 并唤醒阻塞的进程/线程去重新轮询,对其中的 epitem 调用 ep_item_poll() 取回就绪事件,效率明显更高。
虽然理论很美好,但是在实践中似乎还没有强有力的、广泛认可的 benchmark 数据来证明这一点,因为网络应用本身可以非常复杂,因此其性能通常会受到很多因素的影响,想要剥离掉其他影响因子而单纯地验证 LT 和 ET 之间的性能差异比较困难,反而因为 LT 模式相比 ET 模式要简单得多所以不容易写出 bugs,通常开发网络应用时还是会优先选择 LT 模式。然而,ET 模式也不是就没有用武之地了,在某些特定的场景中 ET 模式是可以实打实地提升网络性能的,就比如前面那一章 “Edge-triggered 模式” 中提到的 Realm 利用了 ET 模式来积累 pipe 的 readable 事件并最终一次性读取完所有的数据,节省系统调用。
另外一个比较典型的应用是 epoll + eventfd/pipe 实现的通知机制。在 epoll 编程中,eventfd 通常被用作一种通知机制:将 eventfd 注册到 epoll 实例中,因为 epoll_wait(2) 会在没有就绪事件的时候阻塞住,如果这时候你想要唤醒主线程去执行其他逻辑,比如一些异步任务或者定时任务,则可以往 eventfd 里写数据唤醒 epoll_wait(2),如果使用的是 LT 模式,那么唤醒主线程之后即便我们并不需要 eventfd/pipe 中的数据,也需要每次都调用 read(2) 将 eventfd/pipe 清零,否则内核会一直唤醒主线程,造成 busy loop。但是如果改用 ET 模式,则唤醒之后便不再需要对 eventfd 调用 read(2) 了,因为 ET 模式下就绪事件不会再被加回 ready list,所以只会唤醒进程/线程一次,程序所需的主动唤醒次数越多,使用 ET 模式对性能的提升越明显。
我前段时间就为 libuv 做过这个优化,性能提升还是比较明显的14。而且经过我后来的调研,这个奇技淫巧在很多其他的世界知名的开源项目中都用到了15,比如 nginx,netty,tokio 等,某种程度上也算是英雄所见略同吧!这个代码贡献的过程比较坎坷,前前后后历经 3 个多月才被合入。最初我都把这个优化的原理背后的 Linux 内核源码贴出来了,我还找了好几年前 Linus 关于这部分的内核的代码和讨论:Linux 的原则是不破坏 API 行为的向后兼容性,即便是一开始内核就把 API 做错了,但只要有人用了,就算是错的也得坚持不能改!所以 Linus 承诺内核会一直保留这个“bug”7 16。然而其中一个 maintainer 还是坚持说 man pages 上最好能有明确的关于这部分的描述,这样以后就算内核团队真的打算打破他们原则把这个“bug”修复,看到 man pages 上的这部分内容就会三思而后行,所以问我能不能去给内核社区提个 patch 补上17,于是我还就真去了18,结果还真成功了19。
虽然 man pages 目前的 maintainer —— Alejandro Colomar 在整个过程中都表现得很 nice,不过我还是要吐槽一下 kernel 社区用落伍的 mailing list 维护源码的风格,这玩意儿是真的难用 (相较于 GitHub 的工作流模式来说),我猜是不是因为来自 UNIX 和 GNU 时代的老家伙们用顺手了所以不愿意改了🙄,mail 里还不能带任何一点 HTML 代码,必须是 plaintext 纯文本,不然会被服务器自动拒绝,说是为了安全🫠,总之我个人的体验是不太好,而且流程也比较麻烦,还是有一定的上手难度的,以后我有时间的话再写一篇文章介绍一下给 Linux 内核社区提交 patch 的流程。
最后,我相信 ET 模式还有很多其他的妙用,要么已经被应用了,要么还在等待被发掘,如果读者们有相关的经验,欢迎分享!
Epoll 的坑 #
世上没有完美的东西,epoll 当然也不例外。前面讲了那么多 epoll 的各种好,当然也要讲一点 epoll 的坑。事实上 epoll 不仅不完美,在很多开发者眼里 epoll 甚至是一个很糟糕的设计 (像是一个对 kqueue 的拙劣的模仿)。在这里分享三个我个人认为使用 epoll 时最常见的、最容易踩中的坑。
幽灵事件 #
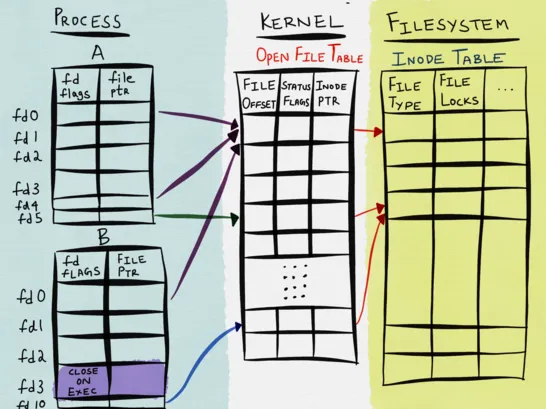
第一个坑是 epoll 本身设计上的缺陷,epoll 用来唯一确定一个监听的文件描述符的 key 是进程的 file descriptor 和内核的 file description。内核使用了三种数据结构来表示一个打开的文件,内核也因此维护了三张表:
- 进程级的文件描述符表
- 系统级的打开文件表
- 文件系统级的 inode 表
针对每个进程,内核为其维护了一个打开文件描述符表 (open file descriptor table),该表中的每一个条目都记录了单个文件描述符的相关信息:
- 控制文件描述符的一组标志。(目前仅定义了一个
close-on-exec标志) - 一个指向内核的 file description (又称为 open file handle) 的指针
内核中还维护了一个系统级的打开文件表 (open file description table,也可以称之为 open file table),该表中的每个条目称之为打开文件句柄 (open file handle 或者 file description),其中包含了如下信息:
- 当前文件偏移量 (调用
read(2)/write(2)时自动更新,也可以使用lseek(2)手动修改) - 打开文件时所使用的状态标志 (调用
open(2)使用的 flags 参数) - 文件访问模式 (只读、只写或者读写模式)
- 信号驱动相关的设置
- 一个指向该文件 inode 对象的指针
最后是文件系统的 inode 表,文件系统上都会有这么一个表,用来记录其存储的所有文件,通常表中的每一项包含的信息如下:
- 文件类型 (比如普通文件、socket 或者 FIFO 等)
- 一个指向该文件所持有的锁列表的指针
- 文件的各种属性,比如大小、所有者、访问权限、访问时间戳等
关于 inode 更具体内容可以参考我的另一篇文章。
这三张表之间的关系如下图所示:
因为 epoll 是使用进程级的 file descriptor 和系统级的 file description 的组合来唯一标识一个监听的文件,而进程级的 file descriptor 只是对 file description 的一个引用,也就是前者和后者是多对一的关系,所以如果你调用 close(2) 关闭 file descriptor 之前没有先调用 epoll_ctl(2) 将这个文件描述符从 epoll 实例中移除掉,而其指向的 file description 还有其他的引用 (比如通过 dup(2) 创建的新 fd),那么 file description 就不会被内核释放,epoll 也就不会从 interest list 删除掉对应的监听文件,只有当该 file description 的所有引用都关闭了,也就是引用计数归零了,它才会被释放,epoll 也会随之移除它。在此之前,假设你有一个注册到 epoll 里的 fd1,然后你又通过 dup(2) 基于 fd1 创建了 fd2,两者都指向内核中的同一个 file description,现在你关闭了 fd1,如果对应的 file description 上发生了就绪事件,epoll 依然会将事件通知给用户程序 (我称之为"幽灵事件”,ghost events),因为 epoll 的 interest list 中对应那个的 file description 还在,但是此时 fd1 已经是无效的了,这就会对用户程序造成疑惑,如果 fd1 被系统分配给另一个新的文件,那情况就更复杂了。
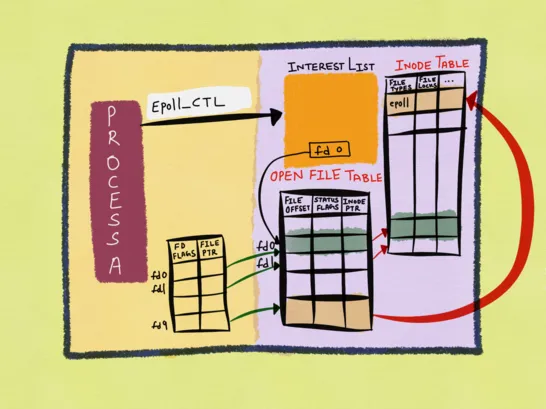
更加糟糕的情况也有,除了 dup(2)/dup2(2) 系统调用之外,fork(2) 也能实现文件共享,而且是在父子进程之间,这种情况就更加复杂了,其中一个进程就算关闭了监听的文件描述符,另一个进程有可能还会收到该文件的 epoll 通知,因为底层的 file description 还在 epoll 实例中。
最要命的是,这种情况没有补救的办法,你不能亡羊补牢调用 epoll_ctl(2) 去移除掉那个文件描述符,因为此时它已经被关闭了,与此同时你也不能在收到(幽灵)事件之后操作它,因为它已经被关闭了。所以,为了避免这种情况发生,在关闭每一个 epoll 监听的 file descriptor 之前必须先将其从 epoll 实例中移除掉,也就是使用 EPOLL_CTL_DEL 操作符调用 epoll_ctl(2)。
饥饿问题 #
第二个坑通常称之为"饥饿问题",本文已经说过很多次了,使用 epoll 的 ET 模式时,收到就绪事件之后需要一直进行 I/O 操作直到系统返回 EAGAIN 错误,也就是在 ET 模式下每次都要尽量处理完所有数据再进行下一轮事件循环,否则可能会导致永远没有机会再处理。这种处理模式可以保证程序不会出错,但是可能会引发"饥饿问题",以服务端读取 socket 数据为例,如果客户端持续发送大量的数据,服务端就可能要一直接收数据从而无法遇到 EAGAIN 错误,于是就不可避免地会将所有 CPU 时间和资源都花在这一个 socket 上,导致服务器没有机会处理其他的 sockets,所以它们被"饿死"了。
这个问题的解决方案通常是设置一个上限值,如果这一轮事件循环读超过这个上限值还没读完,然后以某种方式标记这个 socket 还需要继续处理,后面找机会继续处理,比如 gnet 对这种问题的处理:如果某一个 socket 处理的数据超过上限值,则不再继续,而是手动为该 socket 触发一个唤醒事件,推迟到下一轮事件循环再来处理。不过需要说明的是,“饥饿问题"并不是 epoll 独有的,只要是在处理大块数据的场景中都可以会出现,所以通常需要分批处理这种巨大的数据块。
事件聚合 #
第三个坑比较特殊一点,其实可能在内核看来这是一个优化,但是有时候会在用户程序中引起一些问题:epoll 会将那些在一个很小的时间窗口内触发的事件聚合在一起 (LT 和 ET 模式皆是如此),最后只向 ready list 中插入一个(组合)事件20,这个时间窗口就是两次 epoll_wait(2) 系统调用之间的时差,我们写一个简单的 C 程序来具体分析:
#include <err.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/epoll.h>
#include <sys/eventfd.h>
#include <threads.h>
#include <unistd.h>
int write_eventfd(void *arg) {
eventfd_t val = 1;
int efd = *(int*) arg;
eventfd_write(efd, val);
// struct timespec dur = {0, 10000000}; // 10ms
// thrd_sleep(&dur, NULL);
eventfd_write(efd, val);
return 0;
}
int main(int argc, char **argv) {
int epfd, efd;
struct epoll_event ev;
if ((epfd = epoll_create1(EPOLL_CLOEXEC)) == -1)
err(EXIT_FAILURE, "epoll_create1");
if ((efd = eventfd(0, EFD_CLOEXEC | EFD_NONBLOCK)) == -1)
err(EXIT_FAILURE, "eventfd");
memset(&ev, 0, sizeof(ev));
ev.events = EPOLLIN;
// ev.events = EPOLLIN | EPOLLET;
ev.data.fd = efd;
if (epoll_ctl(epfd, EPOLL_CTL_ADD, efd, &ev) == -1)
err(EXIT_FAILURE, "epoll_ctl");
thrd_t tid;
if (thrd_create(&tid, write_eventfd, &efd) != thrd_success)
err(EXIT_FAILURE, "thrd_create");
int c = 0;
eventfd_t val;
while (1) {
int r = epoll_wait(epfd, &ev, 1, 100);
if (r == -1)
err(EXIT_FAILURE, "epoll_wait");
else if (r == 0)
break;
eventfd_read(efd, &val);
c += r;
printf("epoll got %d events\n", c);
}
if (thrd_join(tid, NULL) != thrd_success)
err(EXIT_FAILURE, "thrd_join");
close(epfd);
close(efd);
exit(EXIT_SUCCESS);
}
在独立的线程中执行 write_eventfd(),对 eventfd 执行两次写入操作,但最终只会触发一次 epoll 事件,程序输出如下:
epoll got 1 events
但如果你把两次 eventfd_write() 之间的代码注释去掉,让线程在这两次写操作之间休眠 10 毫秒,那么你就能收到两次 epoll 事件:
epoll got 1 events
epoll got 2 events
这个坑主要可能会危及的场景通常是那些通知机制:执行多个唤醒操作,由于时间上非常相近,内核会聚合这些事件,最终只唤醒进程/线程一次。这个特性通常会对那些需要精确控制唤醒次数的场景会有负面影响,比如程序需要唤醒主线程 10 次,但是因为 10 次唤醒操作几乎执行,引发事件聚合,最终内核只唤醒主线程一次,这个现象初看像是内核 bug,但其实是 feature。对于其他的场景,比如 TCP socket 通信,对端的多次写操作合并成一个 epoll 事件通知到本端这个行为并不会引发什么问题,反正 TCP 协议会保证数据的完整性,本端收到就绪事件之后直接读就行,反而因为这种合并优化,反而减少了 read(2) 系统调用的次数,效率还更高了。
Linux epoll 的坑还不止是这些,我强烈推荐各位阅读 Epoll is fundamentally broken 1/2 和 Epoll is fundamentally broken 2/2 这两篇文章,全面介绍了 epoll 各种坑,还附带了对应的解决方案,建议仔细研读,这里便不再赘述。另外还需要研读就是 epoll 的 man page,其中关于 ET 模式陈述比较详细,相较于 Linux 关于其他系统调用的手册,这部分内容真的算是很多了,说明内核团队也认为 epoll 的 ET 模式很容易使用不当引发 bugs。
Kqueue #
历史 #
除了 Linux 平台之外,其他平台上也有类似的 I/O 多路复用技术,比如 *BSD/Darwin (macOS/iOS) 上的 kqueue,以及 Solaris/illumos 平台上的 port_getn 等。我这里想重点介绍一下 kqueue,因为它被不少开发者认为是比 epoll 更加优秀的 I/O 多路复用技术21,而且前者也比后者更早推出:kqueue 于 2000 年在 FreeBSD 4.1 版本中实现,而 epoll 要到 2002 年左右的 2.5.44 版本才正式推出,如果说 Linux kernel 团队在开发 epoll 的过程中没有借鉴和参考 kqueue,我估计也没人信吧,我反正是不信。
虽然 Linux 在一众 Unix 操作系统中脱颖而出成为了服务器 OS 市场的最终赢家,但是 Linux 在发展过程中其实从其他 Unix-like OS’s 中汲取很多优秀的技术和理念,除了这里要介绍的 BSD kqueue,其他的比如 socket 最早也是 BSD 系统实现的,也就是 Berkeley sockets,而其他 OS 上的 socket 实现都是衍生自 BSD socket。还有另一个很重要的 Unix-like OS —— Solaris,虽然其母公司 Oracle 在 2018 年发布了 Solaris 11 的最后一个发行版 11.4 之后就已经宣布停止更新,但是 Solaris 当年在操作系统的技术领域那可以真·遥遥领先的,DTrace、ZFS、FMA、Solaris zones 等等都是牛逼哄哄的技术,即便现在 Solaris 已经"死"了,但这些技术遗产已经被其他操作系统继承并大放异彩了,深刻地影响了包括 Linux 和 *BSD 在内的很多后来的操作系统。
所以,我看历史有时候感觉的确挺有意思的,Linux 在当年的一众出身名门的 OS 中并不算出色,然而草根出身的 Linux 却猥琐发育然后屌丝逆袭,在历史上那场操作系统大混战中成功登顶,成为了迄今为止人类历史上最流行的开源操作系统。
LT & ET 模式 #
*BSD 系统上的 kqueue 和 Linux 上的 epoll 一样,都支持 LT 和 ET 模式,默认也是 LT 模式,但同样也支持 ET 模式,可以通过 EV_CLEAR 这个 flag 来开启,它对标的是 epoll 的 EPOLLET 这个 op。这里以 FreeBSD 内核为例,从其源码中可以看出其实现原理和 Linux epoll 非常相似22:
kqueue_scan(struct kqueue *kq, int maxevents, struct kevent_copyops *k_ops,
const struct timespec *tsp, struct kevent *keva, struct thread *td)
{
...
// 分配一个结束标志 knote 以供后续使用
marker = knote_alloc(M_WAITOK);
marker->kn_status = KN_MARKER;
// 遍历 pending list 前先加锁,避免并发竞争
KQ_LOCK(kq);
...
// 在 pending list 的尾部插入一个 knote,表示结束标志,
// 用于在后面的遍历过程中判断是否抵达队列尾
TAILQ_INSERT_TAIL(&kq->kq_head, marker, kn_tqe);
influx = 0;
while (count) { // count 是调用 kevent(2) 时的 nevents 参数,也即请求的就绪事件数
// 开始扫描 pending list,一个个取出 knote 并检查就绪事件
KQ_OWNED(kq);
kn = TAILQ_FIRST(&kq->kq_head);
...
// 已经遍历完了 pending list,如果已经还没有收集到任何就绪事件,重试,否则直接返回
if (kn == marker) {
KQ_FLUX_WAKEUP(kq);
if (count == maxevents)
goto retry;
goto done;
}
...
if ((kn->kn_flags & EV_DROP) == EV_DROP) {
kn->kn_status &= ~KN_QUEUED;
kn_enter_flux(kn);
kq->kq_count--;
KQ_UNLOCK(kq);
/*
* We don't need to lock the list since we've
* marked it as in flux.
*/
knote_drop(kn, td);
KQ_LOCK(kq);
continue;
} else if ((kn->kn_flags & EV_ONESHOT) == EV_ONESHOT) {
// 文件描述符注册时设置了 EV_ONESHOT,表示一次性事件,和 epoll
// 的 EPOLLONESHOT 一样的效果,首次通知用户程序之后就把它从监听
// 列表中移除掉
kn->kn_status &= ~KN_QUEUED;
kn_enter_flux(kn);
kq->kq_count--;
KQ_UNLOCK(kq);
/*
* We don't need to lock the list since we've
* marked the knote as being in flux.
*/
*kevp = kn->kn_kevent;
knote_drop(kn, td);
KQ_LOCK(kq);
kn = NULL;
} else {
// 开始检查 knote 上是否有就绪事件,这个流程和 epoll 的 ep_item_poll()
// 函数的逻辑类似
kn->kn_status |= KN_SCAN;
kn_enter_flux(kn);
KQ_UNLOCK(kq);
if ((kn->kn_status & KN_KQUEUE) == KN_KQUEUE)
KQ_GLOBAL_LOCK(&kq_global, haskqglobal);
knl = kn_list_lock(kn);
// 该 knote 上没有就绪事件,跳过
if (kn->kn_fop->f_event(kn, 0) == 0) {
KQ_LOCK(kq);
KQ_GLOBAL_UNLOCK(&kq_global, haskqglobal);
kn->kn_status &= ~(KN_QUEUED | KN_ACTIVE |
KN_SCAN);
kn_leave_flux(kn);
kq->kq_count--;
kn_list_unlock(knl);
influx = 1;
continue;
}
touch = (!kn->kn_fop->f_isfd &&
kn->kn_fop->f_touch != NULL);
if (touch)
kn->kn_fop->f_touch(kn, kevp, EVENT_PROCESS);
else
*kevp = kn->kn_kevent;
KQ_LOCK(kq);
KQ_GLOBAL_UNLOCK(&kq_global, haskqglobal);
// 文件描述符注册的时候设置了 EV_CLEAR 或者 EV_DISPATCH,
// 那么在内核首次通知用户程序有就绪事件之后就不会重新加回 pending list
// 列表,类似 epoll 的 ET 模式,但是这两种 flag 的后续行为会有一点区别
if (kn->kn_flags & (EV_CLEAR | EV_DISPATCH)) {
/*
* Manually clear knotes who weren't
* 'touch'ed.
*/
// 文件描述符设置了 EV_CLEAR,而且它还没被处理过,
// 则重置这个 knote 的状态和数据,直到再次发生就绪
// 事件之前,这个 knote 都不会再次返回给用户程序
if (touch == 0 && kn->kn_flags & EV_CLEAR) {
kn->kn_data = 0;
kn->kn_fflags = 0;
}
// 文件描述符设置了 EV_DISPATCH,则在内核首次通知
// 用户程序有就绪事件之后关闭通知,直到用户程序手动
// 重新开启通知之前,这个 knote 都不会再次返回给用户程序
if (kn->kn_flags & EV_DISPATCH)
kn->kn_status |= KN_DISABLED;
kn->kn_status &= ~(KN_QUEUED | KN_ACTIVE);
kq->kq_count--;
} else // 默认工作模式,类似 epoll 的 LT 模式,重新将 knote 加回 pending list
TAILQ_INSERT_TAIL(&kq->kq_head, kn, kn_tqe);
kn->kn_status &= ~KN_SCAN;
kn_leave_flux(kn);
kn_list_unlock(knl);
influx = 1;
}
/* we are returning a copy to the user */
// keva 是即将返回给用户程序的就绪事件列表,kevp 是其游标,现在将该指针和计数加一,
// 请求的就绪事件数减一,准备处理下一个 knote,
kevp++;
nkev++;
count--;
// 批量拷贝就绪事件到用户空间,批次是 KQ_NEVENTS,默认是 8
if (nkev == KQ_NEVENTS) {
influx = 0;
KQ_UNLOCK_FLUX(kq);
error = k_ops->k_copyout(k_ops->arg, keva, nkev);
nkev = 0;
kevp = keva; // 游标归零
KQ_LOCK(kq);
if (error)
break;
}
}
// 移除 pending list 尾部的结束标记 knote
TAILQ_REMOVE(&kq->kq_head, marker, kn_tqe);
done:
KQ_OWNED(kq);
KQ_UNLOCK_FLUX(kq);
knote_free(marker);
done_nl:
KQ_NOTOWNED(kq);
// 将剩下的就绪事件拷贝到用户空间
if (nkev != 0)
error = k_ops->k_copyout(k_ops->arg, keva, nkev);
td->td_retval[0] = maxevents - count;
return (error);
}
在 kqueue_scan() 函数中会扫描 pending list (相当于 epoll 中的 ready list) 中的就绪事件并返回给用户程序,如果 knote (相当于 epoll 里的 epitem) 设置了 EV_CLEAR,说明是 ET 模式,则仅仅是清除并重置它的状态,除非该 knote 上再次发生就绪事件,否则未来就没有机会在 pending list 中遍历到它了;而如果是 LT 模式,则将这个 knote 重新加回到 pending list 中,下次用户程序再调用 kevent(2) 的时候会再次遍历 pending list 并检查这个 knote 上是否有就绪事件,有就返回到用户空间,没有则忽略。不难发现这部分逻辑和 Linux 的 ep_send_events() 函数中对应的部分的基本原理是一致的。而 FreeBSD 操作系统的内核中有一个兼容 Linux 的模拟器 —— Linuxulator,其中的代码在使用 kqueue 模拟 epoll 的 EPOLLET 时所使用的就是 EV_CLEAR23,这说明 kqueue 的 EV_CLEAR 至少在表现出来的行为模式上与 epoll 的 EPOLLET 是一样的。
优势 #
我个人认为 kqueue 优于 epoll 设计点如下:
- 没有幽灵事件。kqueue 注册的事件是通过
(ident, filter)二元组来唯一标识的,macOS 的话则再加上一个udata,但是通常这个字段是置空的,所以可以认为二元组就是唯一的 key。ident一般是进程中的文件描述符,所以 kqueue 和 epoll 不同,它并不使用内核的数据结构作为 key,因此一般情况下没有 epoll 中的幽灵事件,在 *BSD 和 macOS 系统上调用close(2)关闭文件描述符之后,如果这些文件描述符之前在 kqueue 中注册过,kqueue 会自动移除掉相关的事件,也就是说使用 kqueue 时不需要像 epoll 那样严格地先手动移除事件再关闭文件描述符,直接关闭文件描述符即可。 - 没有组合事件。正如前文介绍过的那样,对于某一个监听的文件描述符,epoll 可能会一次性上报所有的就绪事件,也即是事件聚合,前面我介绍的例子是多个读事件的聚合,而不同类型的事件也可以被内核聚合在一起,我们暂且称之为组合事件,比如
EPOLLIN和EPOLLOUT可以通过位操作|(“或”) 将其组合在epoll_event.events中一次性返回给用户程序,而在 kqueue 中则不会有这种情况,因为读写事件是独立的,使用kevent.filter区分,每个事件只可能是EVFILT_READ、EVFILT_WRITE或其他的一种,如果文件描述符同时可读和可写,则返回两个事件。这种设计使得基于 kqueue 的程序通常会更加简洁清晰:一次事件循环只处理一种类型的就绪事件。而不是像 epoll 程序那样一个 event loop 要处理所有可能的就绪事件,代码更加复杂,可读性也稍逊一筹。 - 支持批量添加/修改监听的文件描述符,相较于
epoll_ctl(2)一次只能添加/修改/删除一个文件描述符,kevent(2)系统调用支持批量操作,可以一次性添加/修改/删除多个文件描述符,这对性能提升有很大的帮助,尤其是那些需要频发操作 interest list 的场景。Linux 曾经有一个 patch 尝试新增一个epoll_ctl_batch()系统调用24,支持批量操作文件描述符,但是不知道为什么没有继续推进下去,现在也不了了之了,Linux 内核团队后来也产生了一些关于 epoll 的未来发展的思考25,不过随着后来异步 I/O 框架io_uring的推出,由于其 API 的强大性,支持批量提交异步任务,调用 Linux 上的任意系统调用,批量操作 epoll 监听的文件描述符这个需求也算是有了一个解决方案,不过io_uring本身使用起来不是很简单,肯定没有像原生的epoll_ctl_batch()这种系统调用用起来更方便。但是随着io_uring对网络 I/O 的支持越来越完善,未来内核中 epoll 那部分代码可能也不会有什么大的改动了,最坏的情况下,网络 I/O 和文件 I/O 一样最终都投入io_uring的怀抱,那么 epoll 这项技术可能就要刀枪入库、马放南山。不过这个预测可能有点过于悲观了,异步 I/O 未必就是万能的,毕竟计算机领域没有银弹,异步 I/O 的性能虽然高,但是复杂度可能更高,同步 I/O 相比之下要简单直接很多,所以 epoll 这种同步非阻塞的 I/O 多路复用技术的价值还是很大,未来应该也不至于完全消失。 - 内置唤醒机制和定时器。这两个功能是 I/O 多路复用技术中比较重要的,先说前者,
epoll_wait(2)/kevent(2)系统调用在没有就绪事件的情况下会阻塞当前进程/线程直到内核收集到就绪事件并返回,或者提前为 polling 设置了timeout,但有时候我们想要在没有事件的时候主动唤醒阻塞在 polling 的进程/线程,这个时候就需要用到唤醒机制了,epoll 的常规做法通常是创建一个eventfd或者pipe并注册到 interest list 中,当需要唤醒正处于阻塞中的epoll_wait(2)的时候就往eventfd/pipe里写入数据,这个模式有两个缺点:1) 需要额外的文件描述符,2) 唤醒之后需要调用read(2)消费掉我们并不关心的数据。虽然前面提到过可以针对性进行优化,比如把pipe替换成eventfd从而将额外的文件描述符从 2 个减少到 1 个,再使用EPOLLET避免唤醒后的read(2)调用,但是就算优化到极致,还是有一个额外的文件描述符;而 kqueue 则内置了一种唤醒事件 ——EVFILT_USER,无需创建额外的文件描述符,直接调用kevent(2)发送该事件就能唤醒处于阻塞中的kevent(2),而且只要指定EV_CLEAR开启 ET 模式,唤醒后就无需进行任何额外的操作,这个内置的唤醒功能可以用来替换掉传统的pipe方式,在那些需要频繁唤醒kevent(2)的场景中会有巨大的性能提升,我曾经为libuv中开发过个功能,效果很显著26。再说后者,Linux 中有一个timerfd可以实现定时器功能,可以和 epoll 配套使用,虽然epoll_wait(2)已经有了timeout参数,但时间精度只能达到毫秒,timerfd使用timespec,也就是说精度可以达到纳秒,Linux 后来实现了epoll_pwait2(2),支持纳秒级别的超时时间,但这是后话了,而且epoll_wait(2)/epoll_pwait2(2)的超时只能基于所有监听的文件描述符,而不能针对其中的某一个,而timerfd则是专门绑定某一个文件描述符,但同样的,timerfd是一个额外的文件描述符。kqueue 中有一个内置的定时器事件EVFILT_TIMER,可以实现和 Linuxtimerfd类似的功能,而不需要任何额外的文件描述符。 - 除了以上介绍的那些优势,kqueue 还有其他零零碎碎的优势,比如支持监听的文件描述符类型更多,功能和特性更丰富等等。
虽说 Linux 目前在服务器 OS 市场中占据了绝对的主流地位,*BSD/Darwin 在服务器市场中存在感不是很强,但是这些相对小众一些的 OS 其实在不少技术领域未必比 Linux 差,甚至有可能在某些特定的层面比 Linux 更加优秀,我们虽然可能平时并不用这些 OS,但是通过学习它们的一些较为领先的技术说不定可以反哺我们的 Linux 平台编程知识,因此我个人认为偶尔跳出 Linux 的"桎梏”,到外面的世界看一看,说不定会有不小的收获,至少我个人经验是这样的。
总结 #
我们在本文中全面而深入地剖析了 Linux epoll 的 LT 和 ET 模式,从应用层的行为模式到内核层的源码实现,由浅入深。之后我又分享了 epoll 在 ET 模式下的一些妙用、奇技淫巧,这些手段技巧和经验总结可以帮助读者编写出性能更高的 epoll 程序,以及规避一些使用上的坑点,通过学习这些知识,未来能够构建出更加高效且健壮的 epoll 程序。
最后,我还介绍了 Linux 之外的另一种 I/O 多路复用技术 —— kqueue,还有它和 epoll 的对比有哪些优势,以及设计上的先进性。主要是希望读者能够跳脱出 Linux 的"桎梏",看一看外面的世界,并从中汲取养分,反哺我们的 Linux 编程技巧。
参考&延伸 #
- Linux I/O 栈与零拷贝技术全揭秘
- The Linux Programming Interface
- epoll(7) — Linux manual page
- FreeBSD Manual Pages —— kqueue(2)
- Linux —— src/fs/eventpoll.c
- Nonblocking I/O
- The method to epoll’s madness
- linux: exploit eventfd in EPOLLET mode to avoid syscall per wakeup
- kqueue: use EVFILT_USER as wakeup event if available
Re: [PATCH 1/1] fs: pipe: wakeup readers everytime new data written is to pipe ↩︎
pipe: avoid unnecessary EPOLLET wakeups under normal loads ↩︎
Regression: epoll edge-triggered (EPOLLET) for pipes/FIFOs ↩︎
[PATCH v5] epoll.7: clarify the event distribution under edge-triggered mode ↩︎
epoll.7: Clarify the event distribution under edge-triggered mode ↩︎
How does kqueue compare to epoll on Linux? —— Hacker News ↩︎
epoll: Introduce new syscalls, epoll_ctl_batch and epoll_pwait1 ↩︎